

Large language models (LLMs) have the ability to engage in conversations that feel remarkably human. Their advanced natural language processing often leads people to expect that these models will always deliver accurate and logical responses. Though tools like ChatGPT provide correct answers there are instances often where they produce convincing but completely incorrect information which is known as hallucination in the AI community.
When users unknowingly hinge on these flawed AI-generated answers to make decisions, the consequences can be especially harmful in fields where accuracy is critical, such as law, healthcare, and finance. In this blog , let’s explore more on LLM hallucination and try to understand why they happen with some real-world examples. To understand the types of LLM Hallucinations please read my previous blog post
What are LLM Hallucinations?
When AI models generate text, they sometimes produce information that’s not accurate or doesn’t match the original content. This is called a “hallucination”.
What causes LLMs to Hallucinate?
Hallucinations have multifaceted origins, spanning the entire spectrum of LLMs’ capability acquisition process. In this blog post, we will explore the root causes of hallucinations in LLMs, primarily categorized into three key aspects:
Hallucinations from Data
Hallucinations from Training
Hallucinations from Inference
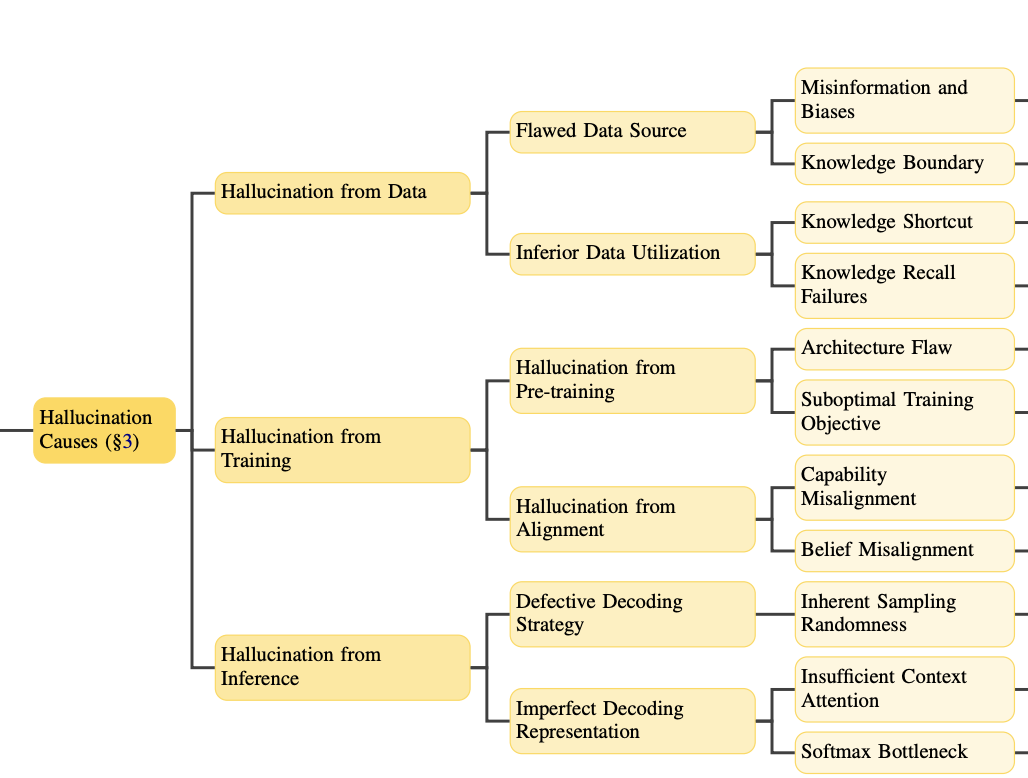
1. Hallucinations from Data
Large Language Models (LLMs) learn from massive amounts of pre-training data, which helps them gain general knowledge and abilities. However, this data can sometimes lead to incorrect or misleading information, known as hallucinations. There are two main reasons why this happens because of data:
Flawed Data Source
Inferior Data Utilization
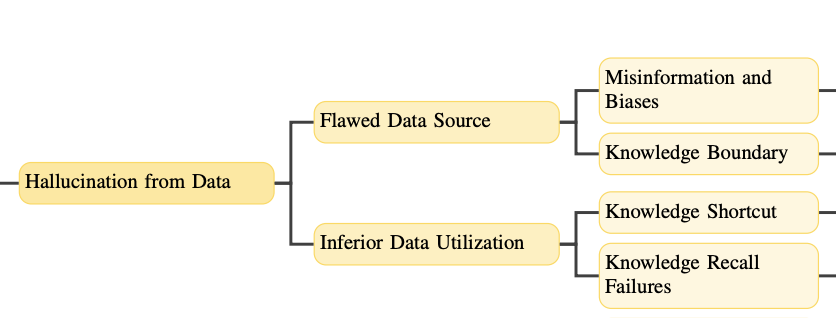
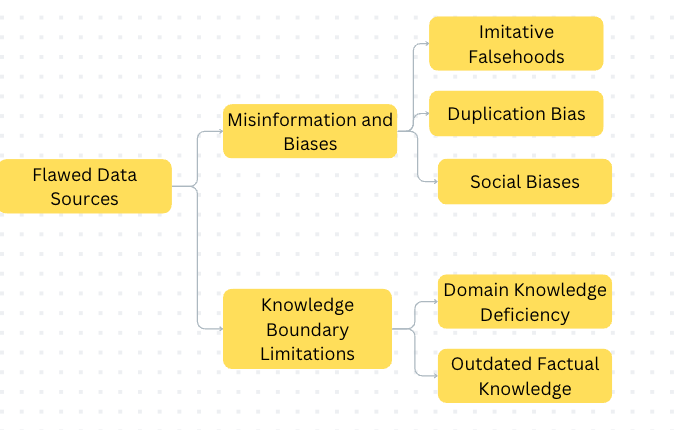
1.1 Flawed Data Source
When we collect a large amount of data, it’s challenging to ensure its quality. This can lead to misinformation and biases in the data, which can then be learned by the LLM. For example, if the data contains incorrect information, the LLM may repeat those mistakes. Additionally, the data might not cover specific topics or be up-to-date, which can limit the LLM’s knowledge in certain areas.
There are two types of problems with flawed data sources that can cause hallucinations:
Misinformation and Biases: When the training data of LLM contains incorrect information or biases, the LLM may learn and repeat those mistakes. For instance, if the data says “Thomas Edison invented the light bulb” (which is actually a myth), the LLM may produce incorrect answers.
Knowledge Boundary Limitations: If the training data lacks specific knowledge or is outdated, the LLM may not be able to provide accurate answers in certain situations.
Misinformation and Biases
Let’s explore some examples of how flawed data (Misinformation and Biases) can lead to hallucinations:
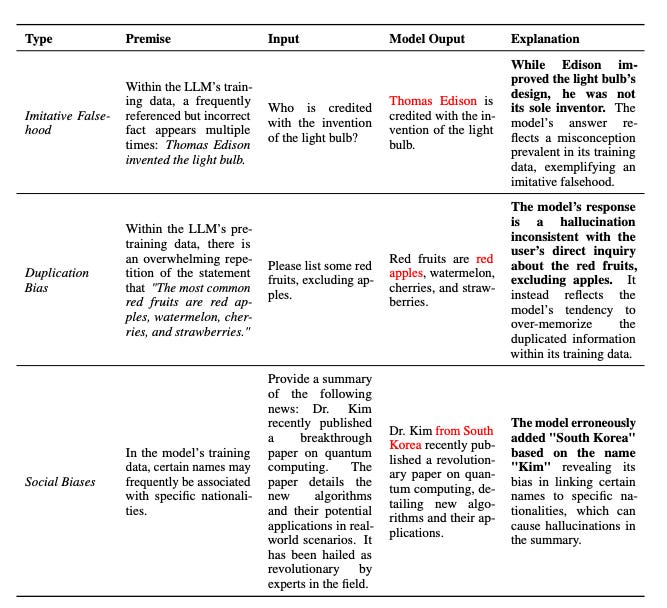
Imitative Falsehoods: When the LLM is trained on incorrect data, it may amplify those mistakes, leading to factually incorrect answers.
Duplication Bias: If the data contains duplicated information, the LLM may memorize that data instead of understanding the context. This can lead to hallucinations that are not relevant to the topic.
Social Biases: The data may contain biases related to gender, nationality, or other factors, which could be picked up by the LLM and leads to hallucinations. For example, the LLM may associate a profession with a specific gender, even if it’s not mentioned in the context.
These biases can be introduced into the data through various sources, like internet-based texts, and can then be propagated into the generated content.
Knowledge Boundary Limitations
Large Language Models (LLMs) are trained on massive amounts of data, which gives them a lot of factual knowledge. However, there are limits to what they know. These limits can be seen in two areas:
Domain Knowledge Deficiency
Outdated Factual Knowledge
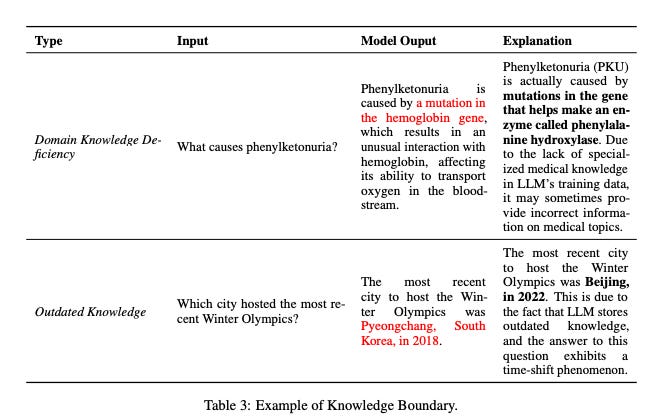
Domain Knowledge Deficiency
LLMs are great at performing tasks in general areas, but they may struggle with specialized domains like medicine or law. This is because they’re trained on publicly available data, which may not cover specific areas of expertise. That’s why, when they’re asked questions that require some special/external knowledge, they make up facts or provide incorrect answers.
Outdated Factual Knowledge
Another problem with LLMs is that their knowledge can become outdated very quickly. The facts they’ve learned from their training data may not be updated, even if new information becomes available. This means that when they’re asked questions that are outside of their knowledge scope, they might provide answers that were correct in the past but are no longer in the present.
Think of it like this: Imagine you learned a lot of facts in school, but you never updated your knowledge after graduation. You might still remember what you learned, but you wouldn’t know about new discoveries or changes that have happened since then. LLMs face a similar challenge, and it can lead to them providing incorrect or outdated information.
The mindmap should give a good idea of causes due to Flawed data sources.
Love diving into insights like these? Stay ahead in the world of AI with fresh, thought-provoking content delivered straight to your inbox. Subscribe to my Substack today and never miss an update!
1.2 Inferior Data Utilization
Large Language Models (LLMs) are trained on a massive amount of data, which gives them a lot of factual knowledge. However, they can still make mistakes or provide incorrect information due to two main reasons: Knowledge Shortcut and Knowledge Recall Failures
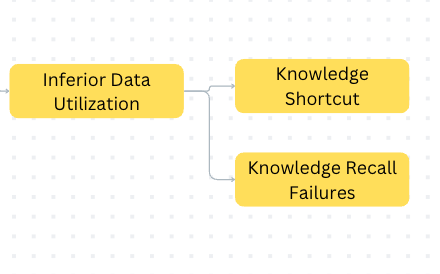
Knowledge Shortcut
LLMs often depends on shortcuts to capture factual knowledge, rather than truly understanding it. They might focus on things like:
The position of words in a sentence
How often certain words appear together
The number of documents that mention a particular topic
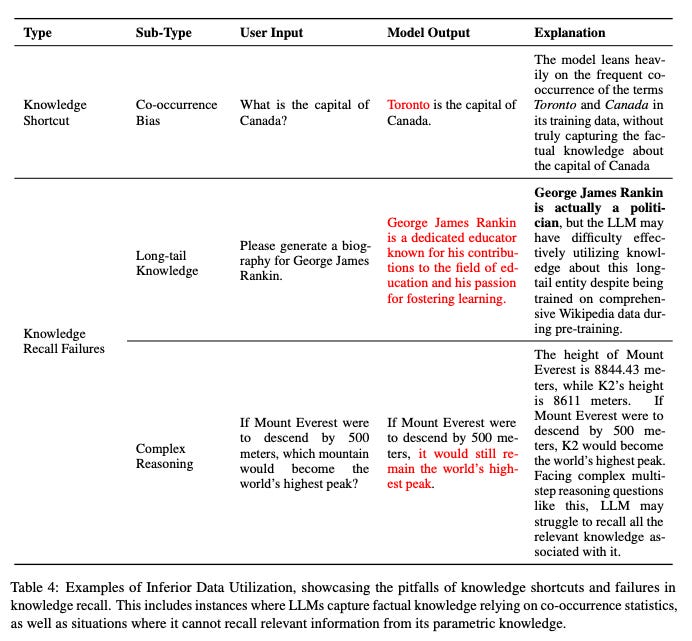
This can lead to biases and incorrect information. For example, if an LLM is asked about the capital of Canada, it might respond with “Toronto” because it saw that combination of words frequently in its training data, even though it’s incorrect.
Knowledge Recall Failures
LLMs can struggle to use their knowledge effectively, leading to hallucinations. There are two main challenges:
Long-tail Knowledge: LLMs might not be able to recall rare or less common knowledge, leading to incorrect responses. For instance, if an LLM is asked about a lesser-known historical figure, it might provide incorrect information.
Complex Scenarios: LLMs can struggle with complex scenarios that require multiple steps of reasoning and logical deduction. For example, if an LLM is asked a question that requires it to use multiple pieces of information to arrive at an answer, it might get it wrong.
These challenges can lead to hallucinations, where the LLM provides incorrect or made-up information. For example, if an LLM is asked to generate a biography for a lesser-known entity, it might attribute the wrong profession or provide other incorrect information.
In summary, LLMs can make mistakes due to their reliance on shortcuts and their struggles with recalling and using knowledge effectively, especially in complex scenarios.
2. Hallucination from Training
The training process of Large Language Models (LLMs) has two main stages:
Pre-training: LLMs learn general knowledge and representations from a massive amount of data.
Alignment: LLMs are fine-tuned to better understand user instructions and preferences.
While this process gives LLMs remarkable abilities, any mistakes or limitations in these stages can lead to hallucinations.
2.1 Hallucination from Pre-training
Pre-training is the foundation of LLMs, where they learn to understand language using a transformer-based architecture. However, this architecture can have some flaws that lead to hallucinations.
Architecture Flaw
LLMs use a transformer-based architecture, which is great for efficient training but has some limitations. Two main issues are:
Inadequate Unidirectional Representation: LLMs only consider the context from one direction (left to right), which can make it hard for them to capture complex dependencies. This can increase the risk of hallucinations.
Attention Glitches: The self-attention module in transformer-based architecture is great for capturing long-range dependencies, but it can sometimes make unpredictable mistakes, especially in algorithmic reasoning. This is because attention can become diluted across positions as the sequence length increases.
These limitations can lead to hallucinations, where the LLM provides incorrect or made-up information.
2.2 Hallucination from Alignment
Alignment is an important step in fine-tuning Large Language Models (LLMs) to make them more useful and aligned with human preferences. However, alignment can also introduce the risk of hallucinations. There are two main types of alignment shortfalls that can lead to hallucinations: Capability Misalignment and Belief Misalignment.
Capability Misalignment
When LLMs are fine-tuned with high-quality instructions and responses, they can learn to follow user instructions and unlock their acquired abilities. However, this can also lead to a mismatch between the LLM’s inherent capabilities and what the alignment data expects them to do. If the alignment data demands more than what the LLM is capable of, it may produce content beyond its knowledge boundaries, increasing the risk of hallucinations.
Belief Misalignment
Research has shown that LLMs have an internal belief about the truthfulness of their generated statements. However, sometimes there can be a mismatch between these internal beliefs and the generated outputs. Even when LLMs are refined with human feedback, they may produce outputs that diverge from their internal beliefs. This is known as sycophancy, where the model tries to please human evaluators at the cost of truthfulness. Studies have shown that models trained with reinforcement learning from human feedback (RLHF) can exhibit sycophantic behaviors, such as pandering to user opinions or choosing clearly incorrect answers. The root of sycophancy may lie in the training process of RLHF models, and both humans and preference models may show a bias towards sycophantic responses over truthful ones.
In summary the causes for hallucination due to training could be better comprehended using the below figure

3. Hallucinations from Inference
When large language models (LLMs) generate text, they use a process called decoding. However, this process can sometimes lead to hallucinations, which are inaccuracies or made-up information. In this section, we’ll explore two main reasons why this happens: the randomness of decoding strategies and imperfect decoding representation.

3.1 Randomness in Decoding
LLMs are great at generating creative and diverse content because they use randomness in their decoding strategies. This randomness helps them avoid producing low-quality text that is too similar. However, this randomness also increases the risk of hallucinations. When the model is more random, it’s more likely to choose uncommon words, which can lead to inaccuracies.
3.2 Imperfect Decoding Representation
When LLMs generate text, they use their internal representation to predict the next word. However, this representation has two main limitations:
Insufficient Context Attention
LLMs can be overconfident and focus too much on the words they’ve already generated, rather than the original context. This can lead to inaccuracies and hallucinations. Additionally, LLMs may not pay enough attention to the entire context, especially when generating long responses.
Softmax Bottleneck
Most LLMs use a softmax layer to predict the next word. However, this layer has a limitation that restricts the model’s ability to produce accurate output probabilities. This can lead to hallucinations, especially when the model needs to choose from multiple possible words.
Closing thoughts:
Hallucinations in Large Language Models (LLMs) have become a significant problem because of their impact on the reliability of these models in real-world applications. As LLMs improve in generating human-like text, the challenge of distinguishing accurate information from hallucinated content becomes increasingly difficult. Mitigating these hallucinations involves two key areas: developing detection mechanisms and establishing evaluation benchmarks. In the next post, we’ll dive into these aspects, exploring how hallucination detection works and what benchmarks are used to evaluate the effectiveness of these methods.
References:
[1] Lei Huang et.al, A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions
Enjoyed this article? Subscribe to my publication for regular updates on AI, delivered in a clear and easy-to-understand way!