
Lesson 8.5: What is a knowledge graph and when does GraphRAG win?
Mastering RAG - Brain Friendly way - Module 8: Advanced Retrieval Patterns

Embeddings are great at finding text that looks similar, but they’re blind to the explicit relationships that connect entities across your documents. When questions demand chaining facts, traversing connections, or seeing the big picture across an entire corpus, vector search hits a wall. In this lesson, we’ll explore how knowledge graphs and GraphRAG turn retrieval from “find similar chunks” into “walk the map of how things actually connect.”
Note: The companion notebook for this lesson is available here. You could follow along and play around with the full code implementations of the concepts explained here.
Vector embeddings are remarkable at capturing topical similarity. Two passages about machine learning will land near each other, even if they share no exact words.
But embeddings are blind to Explicit relationships between entities.
Consider this corpus:
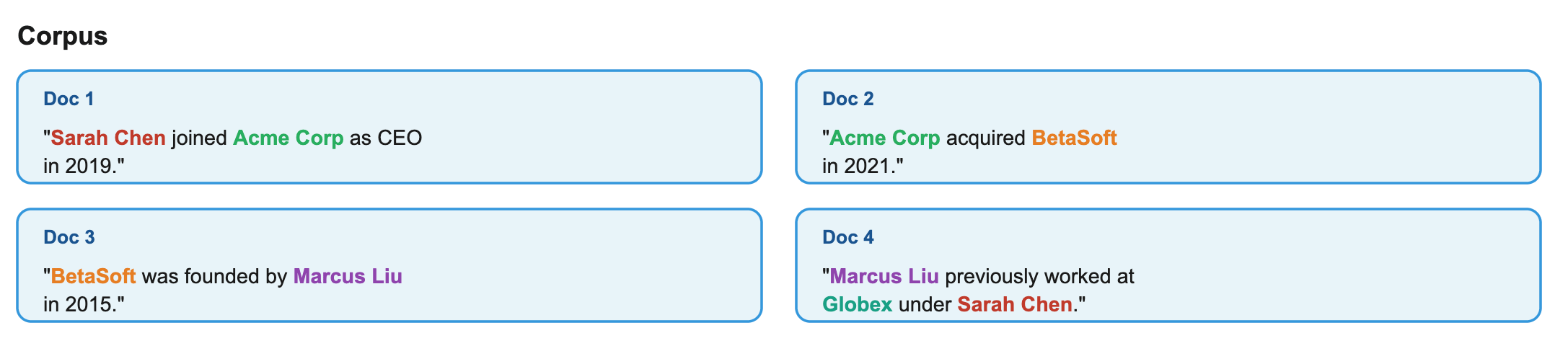
Now ask: “What’s the connection between Sarah Chen and Marcus Liu?”
A vector search will dutifully retrieve documents that mention these names. But the answer, that they worked together at Globex, then reconnected through Acme’s acquisition of BetaSoft requires chaining facts across documents along a path:
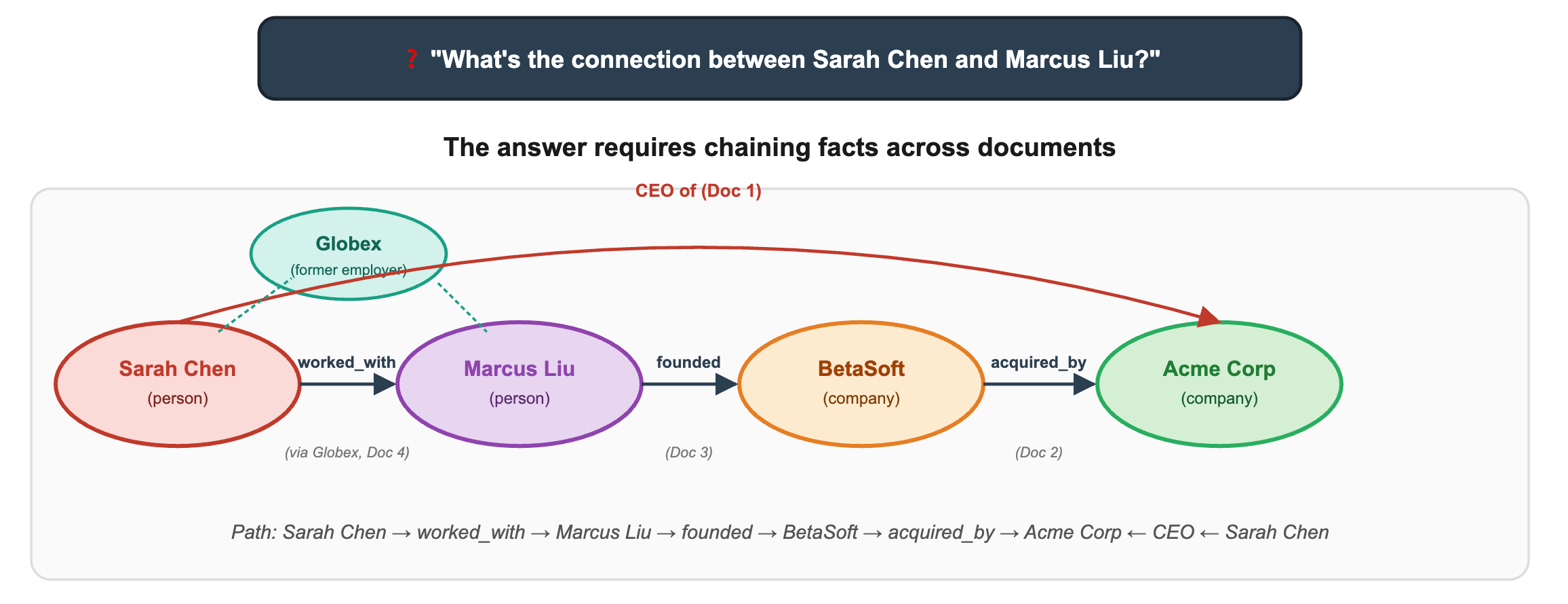
There’s no single chunk that contains this chain. Embeddings can’t see the chain. They only see “documents that look similar.”
This is where knowledge graphs earn their keep.
What is a knowledge graph?
Knowledge graph (KG): A data structure where nodes represent entities (people, companies, products, concepts) and edges represent typed relationships between them.
The simplest unit of a KG is a triple: (subject, predicate, object).

From our corpus:
(Sarah Chen, joined_as_CEO, Acme Corp)
(Acme Corp, acquired, BetaSoft)
(Marcus Liu, founded, BetaSoft)
(Marcus Liu, worked_at, Globex)
(Sarah Chen, worked_at, Globex)Visually:
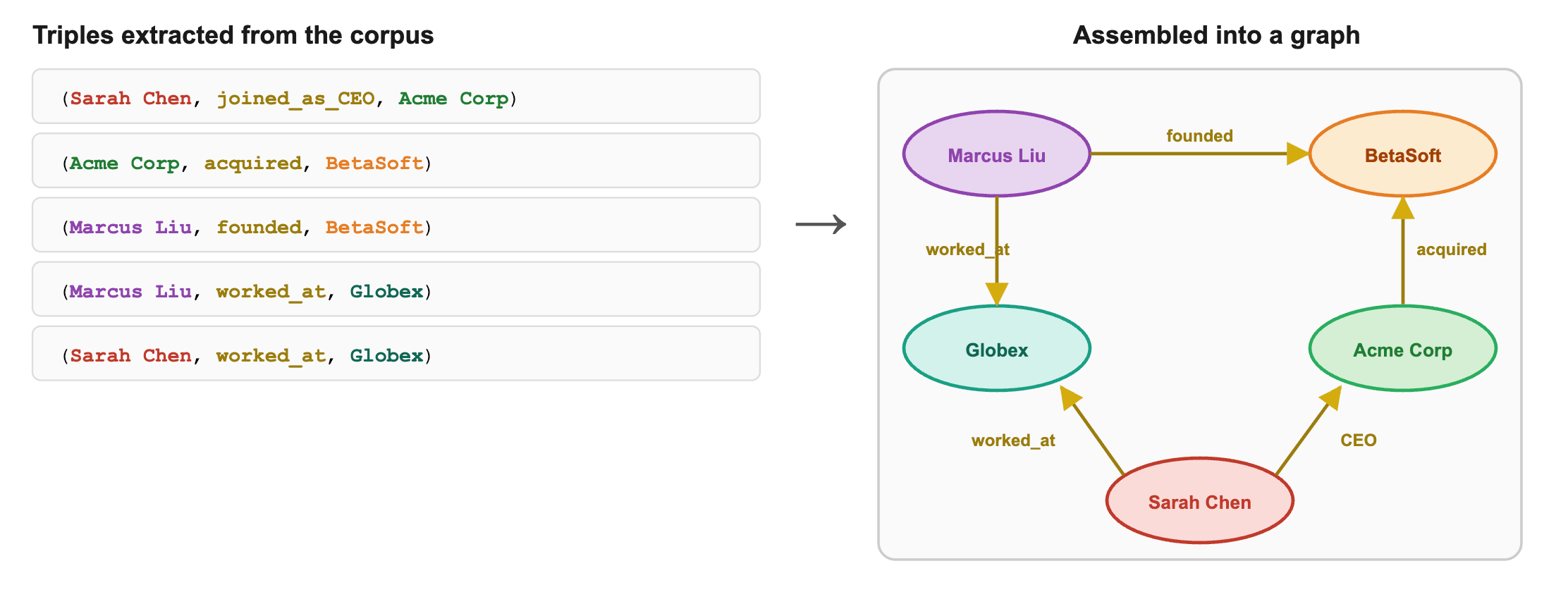
Now you can traverse the graph to answer relational questions. The question “How are Sarah and Marcus connected?” becomes a graph walk: find paths between Sarah Chen and Marcus Liu. The graph reveals two connections instantly.
That’s something no embedding will ever give you.
So what is GraphRAG?
GraphRAG is RAG that uses a knowledge graph (instead of, or alongside, a vector index) as the retrieval substrate.
How GraphRAG works?
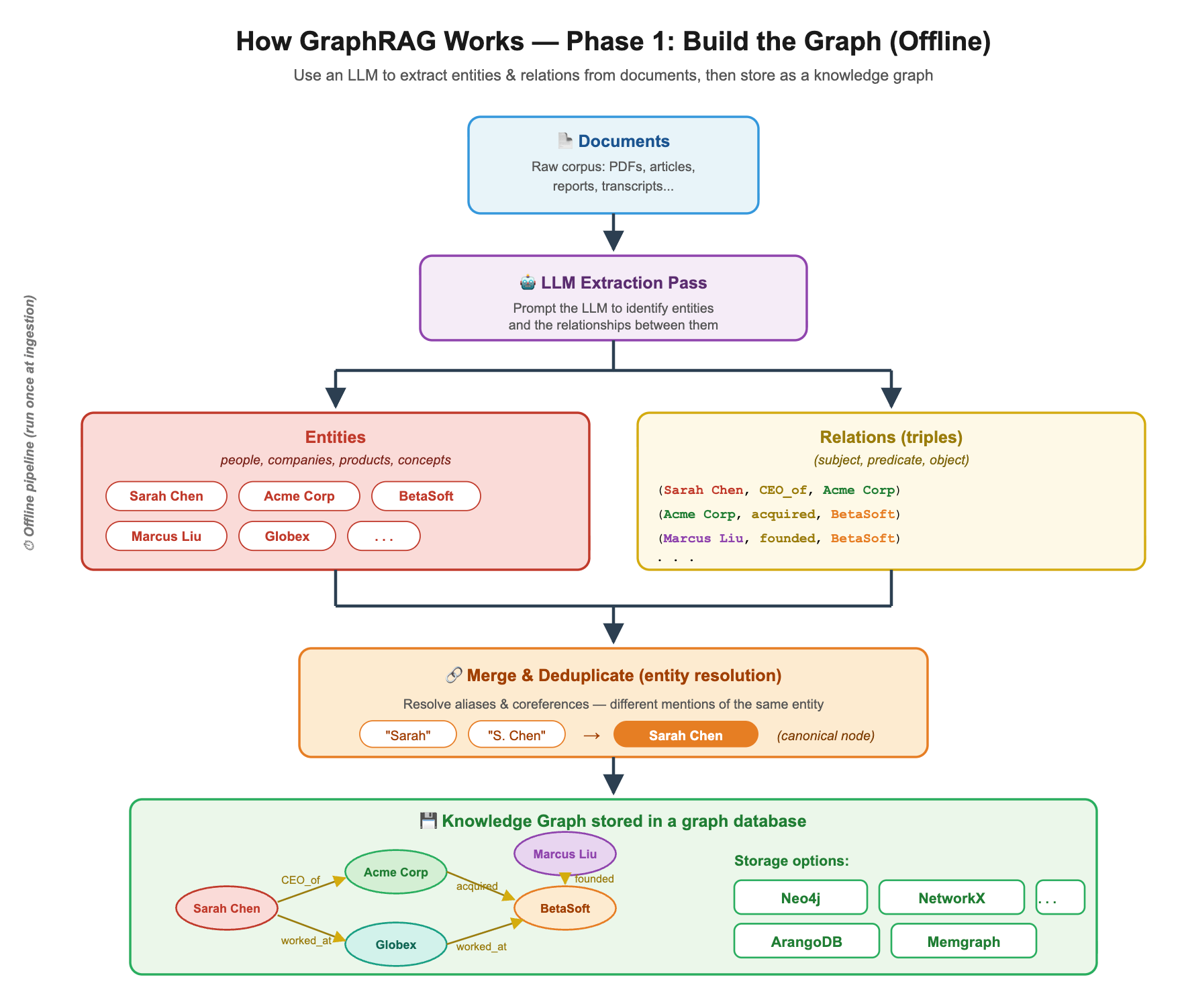
Phase 1: Build the graph (offline)
Phase 2: Query the graph (online)
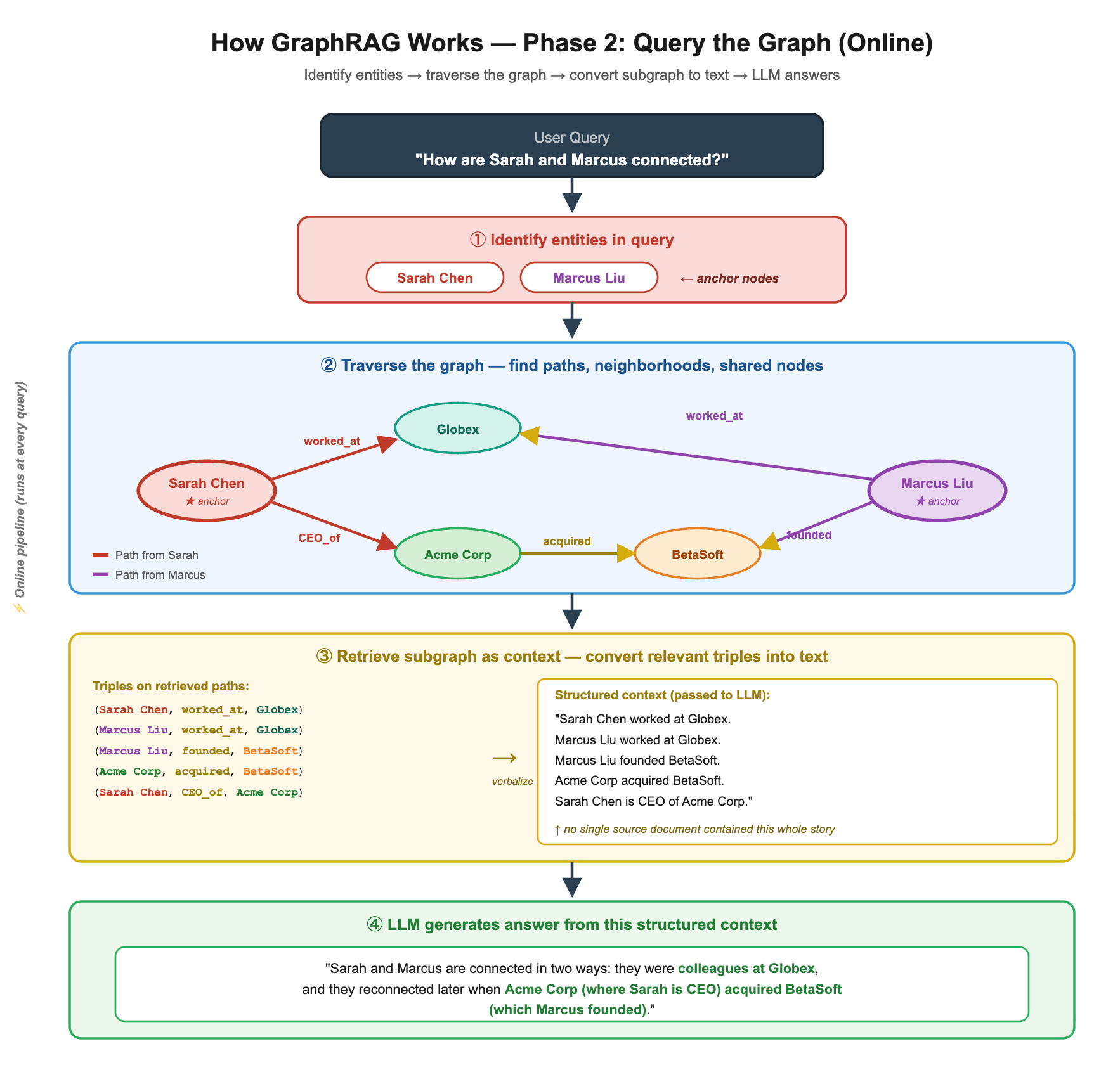
The LLM no longer has to infer the connection from scattered prose. The graph hands it the answer on a silver platter, in the form of explicit, atomic facts.
Microsoft GraphRAG:
In 2024, Microsoft Research published GraphRAG, which took the basic idea and added two ingredients that matter at scale.
Ingredient 1: Community detection
A real-world graph from a corporate document corpus can have millions of nodes. You can’t traverse the whole thing for every query. So GraphRAG runs a community detection algorithm (like Leiden) to cluster the graph into groups of densely-connected entities.
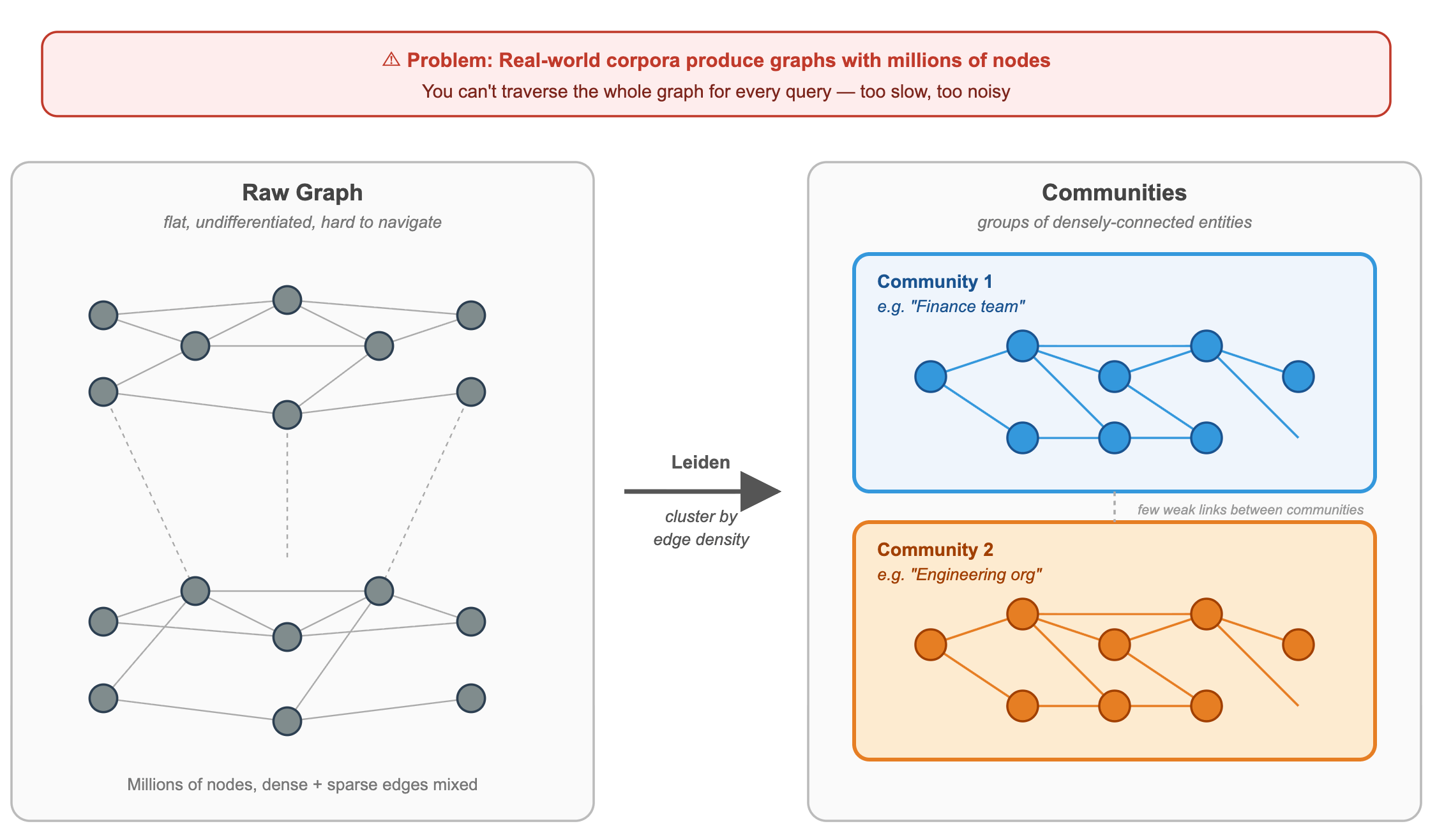
Each community represents a theme in your data, like an automatically discovered taxonomy.
Ingredient 2: Hierarchical summarization
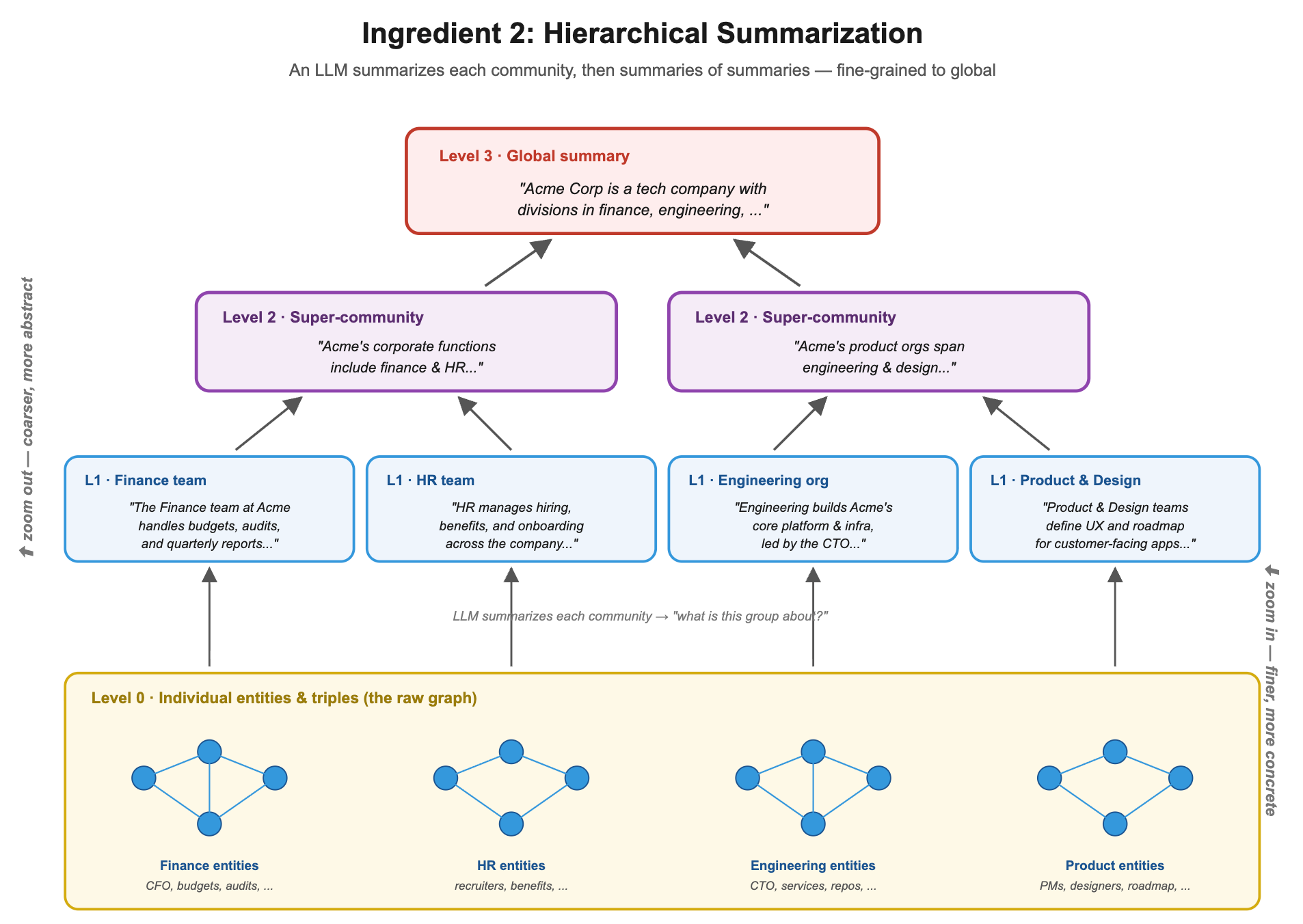
For each community, GraphRAG asks an LLM to write a summary of what that community is about. Then it summarizes communities of communities, building a hierarchy of summaries from fine-grained to global.
Two query modes: local vs global
This hierarchy unlocks two flavors of question that vanilla RAG can’t do well:

Vanilla RAG is bad at global questions because no single chunk contains the “big picture” — it’s an emergent property of the whole corpus. Hierarchical summarization gives the LLM a way to see the forest, not just the trees.
What this looks like in code?
A minimal implementation using networkx and an LLM:
import networkx as nx
from openai import OpenAI
client = OpenAI()
def extract_triples(text: str) -> list[tuple[str, str, str]]:
“”“Use LLM to extract (subject, predicate, object) triples.”“”
prompt = f”“”Extract factual triples from this text.
Return as: subject | predicate | object
Text: {text}
Triples:”“”
response = client.chat.completions.create(
model=”gpt-4o-mini”,
messages=[{”role”: “user”, “content”: prompt}],
)
return parse_triples(response.choices[0].message.content)
# Build graph
G = nx.DiGraph()
for doc in documents:
for subj, pred, obj in extract_triples(doc.text):
G.add_edge(subj, obj, relation=pred)
# Query: find paths between two entities
def query_graph(entity_a: str, entity_b: str):
paths = nx.all_simple_paths(G, entity_a, entity_b, cutoff=4)
context_triples = []
for path in paths:
for u, v in zip(path, path[1:]):
rel = G[u][v][”relation”]
context_triples.append(f”{u} {rel} {v}”)
return context_triples
context = query_graph(”Sarah Chen”, “Marcus Liu”)
# → [”Sarah Chen worked_at Globex”, “Marcus Liu worked_at Globex”, ...]For production-grade systems, you’d reach for:
Microsoft GraphRAG (github.com/microsoft/graphrag) — full pipeline including community detection
LlamaIndex KnowledgeGraphIndex — simpler but production-ready
Neo4j + LangChain — when you need a real graph database
kg-gen — quick triple extraction from text
When GraphRAG wins decisively?
GraphRAG isn’t always better. But when it wins, it wins by a wide margin. Here’s where it shines:
1. Relational questions
“Which companies in our portfolio share a board member with Acme Corp?”
This is a graph traversal, not a text search. GraphRAG nails it. Vanilla RAG can’t even start.
2. Multi-hop factual questions
“What’s the connection between our Q3 revenue dip and the regulatory change in Singapore?”
Requires chaining: Q3 dip → caused_by → product launch delay → caused_by → supplier issue → caused_by → regulatory change. The graph encodes each link explicitly.
3. Corporate knowledge with organizational structure
Org charts, project dependencies, system architectures, supply chains, scientific literature with citation networks — anywhere your data has inherent relational structure, a graph captures it natively while embeddings flatten it.
4. Global “big picture” questions
"What are the dominant themes in five years of customer support tickets?"
With Microsoft GraphRAG’s hierarchical summaries, this becomes a top-down query against the summary hierarchy. Vanilla RAG can only sample chunks and hope the LLM extrapolates.
When GraphRAG is an overkill?
Be honest with yourself before going down this path. GraphRAG is expensive, both to build and to maintain.

If you can answer most user questions with “find the chunk that contains the answer,” you don’t need a graph. Don’t build a Ferrari to commute three blocks.
The honest cost
Here’s what nobody tells you on the marketing slides:
Building the graph is expensive.
For a corpus of N documents, GraphRAG typically requires:
One LLM call per chunk for entity & relation extraction (often using GPT-4-class models for quality)
Multiple passes for entity resolution and deduplication
Community detection (cheap, but adds compute)
One LLM call per community for summarization (in Microsoft GraphRAG)
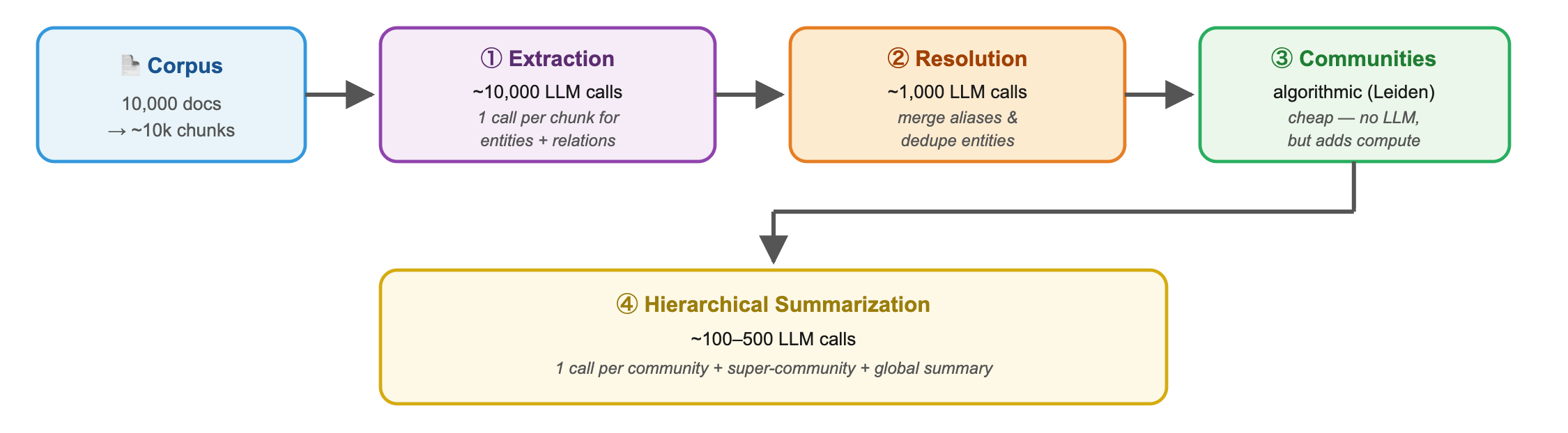
For a 10,000-document corpus, expect:

And every time documents change meaningfully, you may need to re-run parts of this pipeline.
Compare to vanilla RAG: embed once (~$1–10 for 10k docs), and you’re done.
The mental model
Step back. What did adding a graph really change?
Vector RAG says: “Find me chunks that look similar to the question.”
Graph RAG says: “Find me the entities and relationships the question is about, then assemble the relevant facts.”
These are fundamentally different operations:
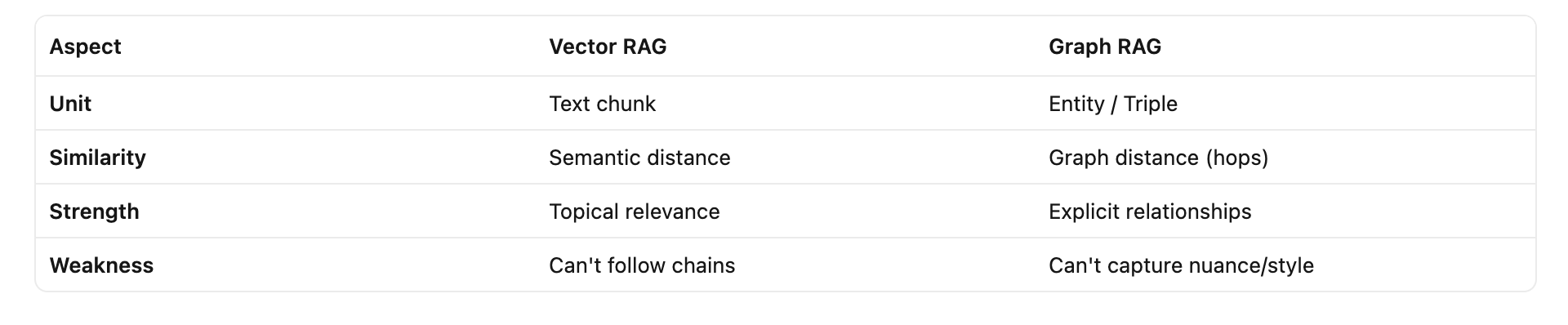
In the wild, the strongest systems use both: the graph for skeleton structure (who relates to whom, how), and vectors for fleshing out each node with the rich textual context that graphs alone can’t capture.
What’s next
Knowledge graphs give your RAG system something embeddings fundamentally can’t: an explicit map of how entities connect. When your questions are relational, multi-hop, or demand a bird’s-eye view of the whole corpus, GraphRAG moves from “nice to have” to “the only thing that works.” Just remember it comes with real costs, so reach for it when your data’s structure genuinely demands it.
Next up: Self-RAG and Corrective RAG, where we’ll see how RAG systems can critique their own retrievals and course-correct when things go wrong.