
Lesson 7.2: What is context stuffing and why does it backfire?
Mastering RAG- The Brain Friendly Way: Module 7: Making the LLM Use What You Retrieved

You've nailed chunking. Your retriever is pulling back the right documents. So why does your LLM still fumble the answer? In this lesson, we'll uncover context stuffing, the silent killer of RAG quality and learn why more context is often the worst advice you can follow.
While building your First RAG many developers would think “What if I just give the model more context? Surely 10 chunks beat 3.”
And they would crank top-k from 3 to 10 and ship it.
Quality drops. Latency goes up. Cost goes up. And worst of all, the model now misses answers it used to get right.
This is context stuffing — the most counterintuitive failure mode in RAG.
The Lost in the Middle Phenomenon
In 2023, Liu et al. published a paper “Lost in the Middle: How Language Models Use Long Contexts” that quietly changed how serious RAG engineers think about prompts.
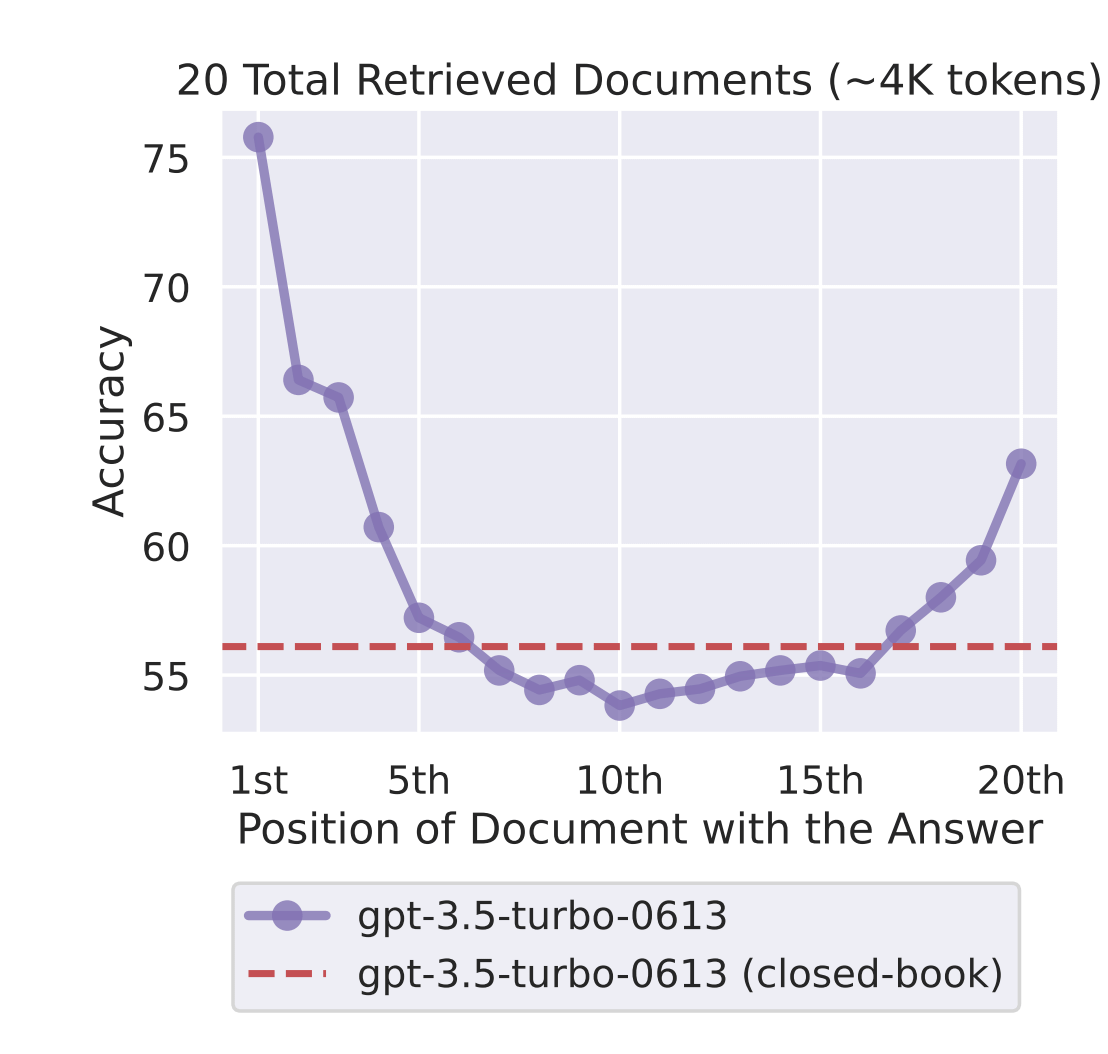
They gave models a question and a list of documents. Exactly one document contained the answer. They varied where in the list that golden document appeared — position 1, 5, 10, 15, 20 and measured accuracy.
The result looked like this:
The result looked like this:
Changing the location of relevant information (in this case, the position of the passage that answers an input question) within the language model’s input context results in a U-shaped performance curve.
Models attend strongly to the beginning (primacy bias) and the end (recency bias) of their context window. Information in the middle is like a quiet voice in a noisy room which is technically present, practically ignored.
🆕 Why does this happen? It’s a side effect of how transformer attention is trained. Models see countless examples where instructions appear at the start of a prompt and conclusions/answers appear at the end. Over time, attention weights skew toward those positions. The middle becomes a “low-attention zone”, not because the model can’t see it, but because it’s learned not to prioritize it.
Why This Matters for RAG?
When you retrieve top-10 chunks and stuff them into a prompt, what happens?
The retriever ranks chunks by relevance: chunk_1 most relevant, chunk_10 least.
You put them in the prompt in that order.
The model attends most to chunk_1 (start) and chunk_10 (end).
Chunks 4, 5, 6, 7 in the middle get ignored.
Your retriever isn’t perfect. Sometimes the truly best chunk is ranked #5, not #1. So the chunk that actually contains the answer gets buried exactly where the model can’t see it.
You retrieved the right answer. The model just couldn’t reach it.
🪧 Mental model: Stuffing context is like handing someone a 50-page report and saying “the answer is in here somewhere.”
Context Length vs. Quality
Most developers assume:
Example:
More context ──► More info ──► Better answersThe reality
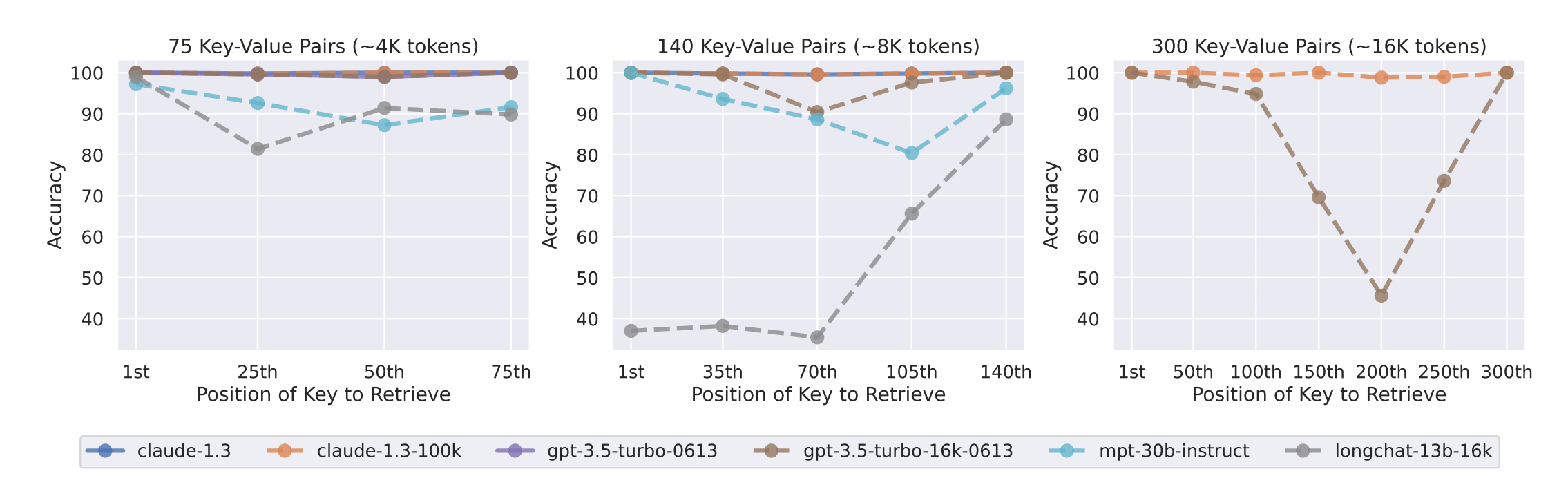
The reality:
The effect of changing the input context length and the position of relevant information on key-value retrieval performance.
There’s a sweet spot. Past it, every additional chunk:
Dilutes attention across more tokens 🆕 (the model has a finite “attention budget” — spreading it across 10 chunks means each chunk gets less focus than it would in a top-3 setup)
Adds irrelevant or marginally-relevant noise 🆕 (chunks ranked 7–10 are often only weakly related to the query, and the model can get distracted by them — sometimes even hallucinating answers based on near-misses)
Pushes the actually useful chunk toward the dreaded middle
Costs more money and time 🆕 (LLM pricing scales with input tokens, and longer contexts mean slower responses — both of which hurt user experience and your bill)
The curve doesn’t just flatten — it bends back down.
The Practical Consequence: Top-3 Often Beats Top-10
This is the part that makes engineers gasp:
In production RAG systems, retrieving top-3 chunks often outperforms retrieving top-10.
Why?
3 chunks fit comfortably in the high-attention zones (start + end).
Less noise → cleaner reasoning.
Lower latency, lower cost.
The “middle” barely exists with only 3 items.
This doesn’t mean top-3 is always optimal. But it means bigger top-k is not free, and you should measure before assuming more retrieval = better answers.
⚠️ Counterintuitive but true: if your retriever has decent recall in its top-3, adding chunks 4–10 often hurts more than it helps.
Position Bias: Put the Most Relevant Chunk First
Since the model attends most to the beginning and end, here’s a small change with outsized impact:
Order your retrieved chunks so the most relevant one is FIRST, not last.
Many developers naively pass chunks in the order their retriever returned them, but they don’t double-check that “first returned” actually means “most relevant.” Worse, some pipelines accidentally reverse the order during post-processing.
A simple heuristic:
Example:
Position 1 (start) → most relevant chunk
Position 2 → second most relevant
Position 3 (end) → third most relevantIf you have more chunks, some teams use a “bookend” strategy: put the top-1 at the very start and the top-2 at the very end — sandwich the rest in between (and accept that the middle ones are mostly there as supporting evidence).
Example:
[Most relevant] ← high attention
[3rd relevant]
[5th relevant] ← supporting, partially attended
[4th relevant]
[2nd relevant] ← high attentionThis isn’t magic — it’s just respecting how the model actually reads.
When Stuffing Actually Helps
Before you swear off context entirely, here’s the nuance:
Context stuffing is bad when precision matters. It’s fine when completeness matters.
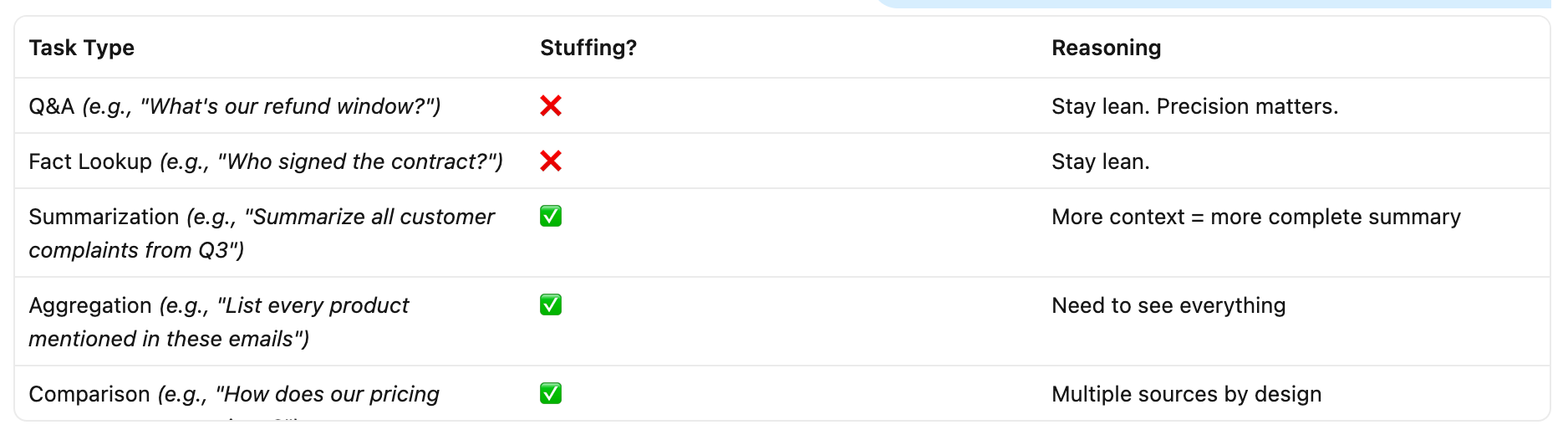
What To Do Instead
If you’re tempted to stuff, try these in order:
Lower your top-k. Start with 3. Measure. Increase only if accuracy improves. Don’t trust intuition here — actually run an eval set with k=3, k=5, k=10 and compare.
Re-rank before stuffing. Use a cross-encoder (like
bge-rerankeror Cohere Rerank) to reorder retrieved chunks so the truly relevant ones land in positions 1 and N. Cross-encoders are slower than embedding-based retrieval but far more accurate at judging relevance, because they look at the query and chunk together rather than comparing pre-computed vectors.Compress. If you have 10 chunks, summarize each into 2 sentences before passing them in. (This is its own technique — covered later.) This lets you preserve breadth of information while shrinking the token count, keeping more useful signal in the high-attention zones.
Filter by score. If chunk 7’s similarity score is way below chunk 3’s, drop it. Don’t include weak chunks just because top-k said so. A common rule: discard any chunk whose score is less than 80% of the top chunk’s score. Hard cutoffs prevent “filler” chunks from polluting your prompt.
Place strategically. Put the strongest chunk first.
Context stuffing feels like generosity to the model, but it’s actually noise in disguise. In RAG, less context placed intentionally almost always beats more context dumped hopefully, so retrieve lean, rank smart, and respect the U-shaped curve.
Next up, we’ll tackle the flip side: what do you do when you genuinely have more relevant chunks than can fit?