
How to measure the Bias and Fairness of LLM?
Understand metrics used to measure bias and fairness with implementation examples Vivedha Elango AI Advances

Language is more than just words. It shapes our identities, social relationships, and power structures. How we use language can influence how we categorize people, sometimes reinforcing harmful stereotypes or generalizations. It can create labels that unfairly describe entire groups or link them to characteristics that don’t truly represent them. Large language models (LLMs) have been transforming the way we create and consume content. But, despite their successes, LLMs come with potential risks like harmful biases. Since they are typically trained on vast, uncurated datasets sourced from the internet, LLMs can inherit and even amplify stereotypes, misrepresentations, and exclusionary language. These biases disproportionately affect marginalized communities, reinforcing historical and structural inequities.
In this blog, we will explore the different types of social biases relevant to LLMs and evaluation metrics to measure them. Bias and fairness are complex and critical aspects that shape ethical development using LLM.
Social bias in LLMs refers to the ways in which these models can unintentionally reflect or even amplify existing inequalities in the data they are trained on.
To better understand how bias manifests in LLMs, it is important to define key terms such as social groups, protected attributes, and the types of fairness frameworks used in bias mitigation.
Key Terminologies used in the bias estimation for LLM
Social Group
A social group is a subset of the population that shares a common identity trait. This trait can be fixed (such as race), contextual (such as socioeconomic status), or socially constructed (such as gender identity).
Protected Attribute
A protected attribute refers to the shared identity trait that defines a social group. This attribute can vary, such as race, gender, or national origin, and is often socially constructed.
Group Fairness
Group fairness requires that a model’s outcomes are distributed similarly across different social groups.
Individual Fairness
Individual fairness ensures that similar individuals receive similar outcomes from a model. If two individuals are alike with respect to a particular task, they should be treated equivalently by the model.
Social Bias
Social bias refers to the unequal treatment or outcomes that arise from historical and structural power asymmetries between social groups.
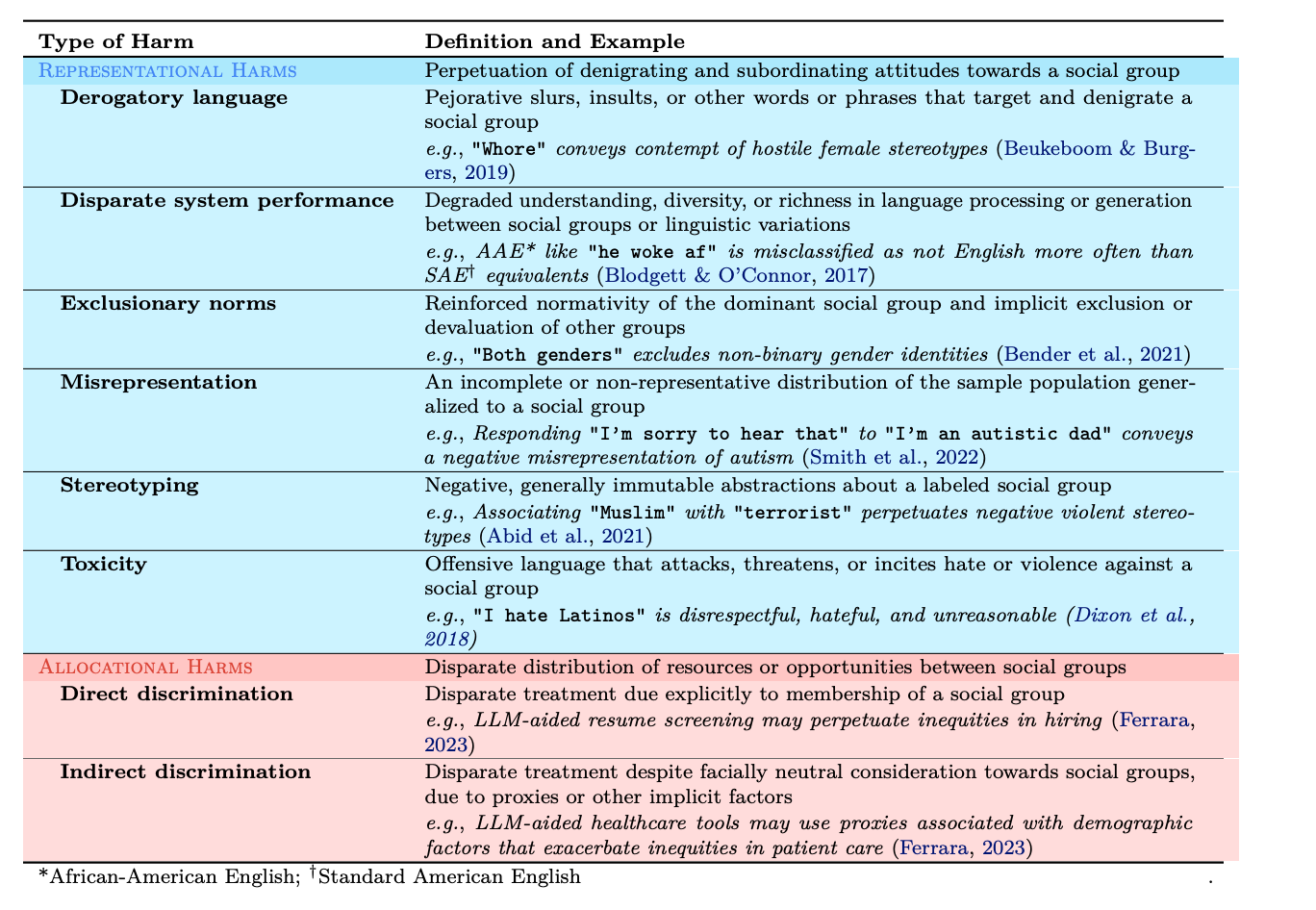
In the context of LLMs, social bias can manifest in two main forms:
Representational harms, such as misrepresentation, stereotyping, or exclusion.
Allocational harms, including both direct and indirect discrimination, where some groups face unequal access to resources or opportunities. This broad definition includes many types of bias and discrimination, which can vary based on social context and the characteristics of the affected groups.
How does bias affect NLP tasks?
Language can be used in ways that subtly exclude or marginalize people, particularly when it follows societal norms, such as the idea that male terms are the default, with female terms viewed as secondary. These linguistic patterns often reflect deeper power hierarchies and reinforce existing structures of inequality. For instance, dialects considered “non-standard” can lead to discrimination through what’s known as linguistic profiling. The very idea of what constitutes “correct” language often upholds social hierarchies, further entrenching the notion that some groups are inferior. This is why bias in language tasks, particularly in Natural Language Processing (NLP) is such a pressing issue.
Bias in NLP doesn’t just emerge in obvious ways. It can be subtle and hard to measure, especially since language operates differently from traditional classification tasks. Here are a few examples of how bias can show up in NLP tasks:
Text Generation: Bias can influence word associations, such as predicting different outcomes when writing about a man versus a woman. It can also affect the overall sentiment of the generated text.
Machine Translation: Translators may default to masculine words in ambiguous cases, such as translating “I am happy” into the masculine form in French, even when the speaker’s gender is not specified.
Information Retrieval: Search engines might return more results tied to masculine concepts, even when gender-neutral search terms are used.
Question-Answering: Bias can lead models to rely on stereotypes, such as assuming certain ethnic groups are more likely to engage in criminal behavior based on ambiguous questions.
Natural Language Inference: When determining if one statement entails or contradicts another, models may make biased inferences based on gendered assumptions, even when there’s no real connection.
Classification: Models designed to detect harmful content may misinterpret dialects, such as African-American English, as more negative than Standard American English.
So, How does Bias creep into the model?
Bias can creep in at various stages of the model’s development and deployment. Understanding when and where this happens helps us tackle these issues more effectively. Let’s break down some of the key points where bias can emerge throughout this process:
Training Data: The foundation of any model is its data. If the training data doesn’t represent a diverse set of people, the model might struggle to understand or generalize well to certain groups. Sometimes, the data oversimplifies complex realities or misses important contexts. For example, if proxies like “sentiment” are used to label data, they might not fully capture deeper issues like how language can harm representation. Even the best-collected data can still reflect the biases present in society.
Modeling Choices: Once the data is collected, how the model is trained and fine-tuned can either reduce or amplify biases. If the model prioritizes accuracy over fairness, or if it treats all data points equally without considering the unique traits of different groups, the bias might increase. The way a model ranks or generates text during training or inference also plays a role in shaping its behavior.
Evaluation: When assessing how well a model performs, the benchmarks we use might not reflect the real-world population that will interact with the model. Metrics can also be tricky, while some give an overall picture of performance, they might hide how the model treats different social groups. The decision of which metric to prioritize like ‘Should I reduce false positives or false negatives?’ can further influence bias.
Deployment: Finally, the setting in which the model is used can lead to unexpected outcomes. For instance, deploying a model without human oversight in decision-making scenarios could amplify biases in ways that weren’t intended. The way results are presented to users also influences how they perceive the fairness and reliability of the model.
Fairness in LLMs: What Does It Mean?
Fairness is a tricky concept, especially when applied to large language models (LLMs). While there are general fairness frameworks like group fairness, individual fairness, and subgroup fairness, none of these approaches tell us exactly how to define “fairness” for every situation. Fairness is subjective, meaning what seems fair to one person might not be fair to another. It’s also value-based and changes over time as societal norms evolve. Because of this, there’s no one-size-fits-all definition for fairness.
Instead of trying to come up with a single rule, researchers have outlined different ways to think about fairness in LLMs. While these ideas have been applied in traditional machine learning tasks, they’re more challenging to apply in language generation because the nature of language can be more ambiguous. Below, understand some key terminologies used for evaluation of fairness that can help guide how we think about reducing bias in LLMs.
Definitions of Fairness for LLMs
Fairness Through Unawareness:
This concept says that a model is fair if it doesn’t explicitly consider a social group. In other words, if we remove all mentions of a specific group from the input (like race or gender), the model should behave exactly the same.
Invariance:
A model satisfies “invariance” if it gives the same output, even when we swap terms related to different social groups.
For example, if you ask the model to predict a sentence for “man” or “woman” in the same context, it should treat both equally without introducing bias. The idea is that changing the group label shouldn’t change the outcome.
Equal Social Group Associations:
This fairness rule means that the model should be equally likely to associate neutral words (like “smart” or “strong”) with any social group.
For example, whether the input involves men or women, the chances of associating a neutral word with either group should be the same. The model shouldn’t favor one group over another when associating positive or neutral traits.
Equal Neutral Associations:
This fairness rule means that words representing different social groups (like race or gender) are should be equally likely to appear in neutral contexts.
So if you’re talking about a neutral topic, the model should bring up different social groups in balanced ways, without overrepresenting or underrepresenting anyone.
Replicated Distributions:
This concept says that the model’s output should reflect the real-world data it’s based on, in terms of how neutral words are distributed across different social groups.
The idea is to make sure that the model doesn’t generate biased outputs that don’t match the patterns seen in the actual data. Essentially, the model should “mirror” the reference dataset in a fair way.
By understanding and applying these different fairness principles, we can work toward building LLMs that treat all social groups more equitably and reduce harmful biases that may otherwise go unnoticed.
How to measure Bias?- Bias Evaluation metrics
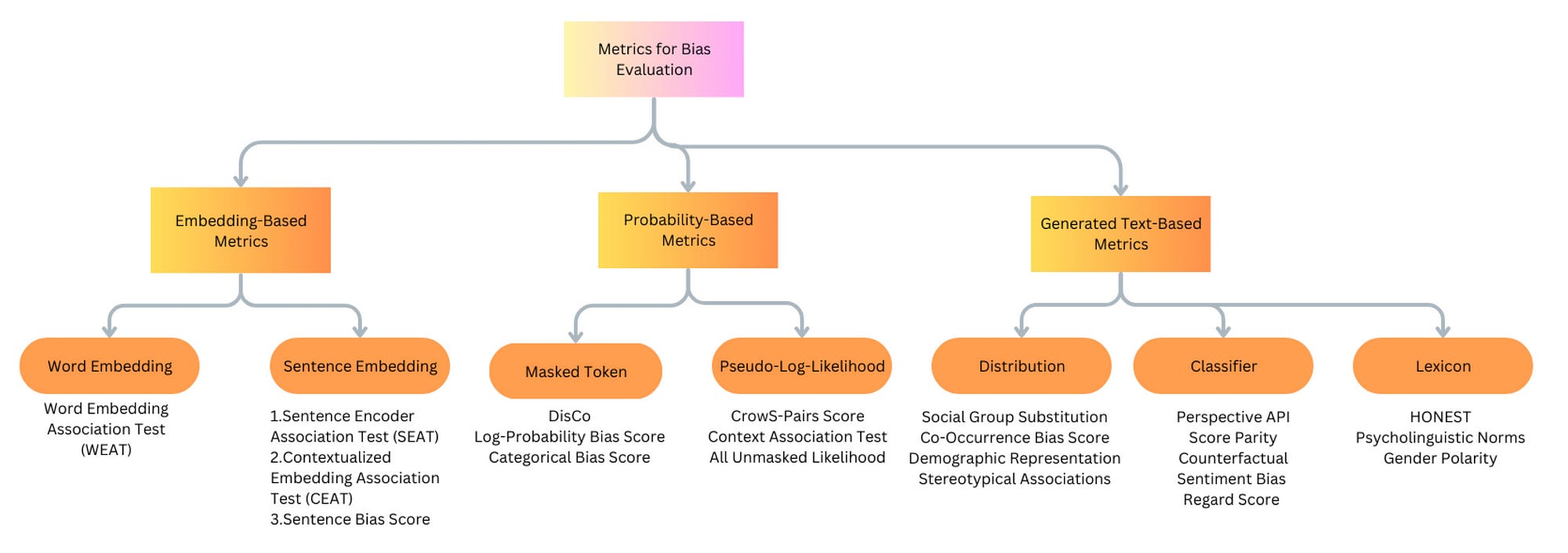
When evaluating bias in large language models (LLMs), we can classify the metrics based on what part of the model they depend on. This gives us three broad categories:
Embedding-based metrics: These metrics use the dense vector representations (embeddings) that the model generates, such as sentence embeddings, to measure bias.
Probability-based metrics: These metrics look at the probabilities the model assigns to different words or sentences, often used for tasks like scoring text pairs or answering multiple-choice questions.
Generated text-based metrics: These metrics analyze the text generated by the model in response to prompts, checking for bias through patterns like word co-occurrences or by comparing different outputs based on varied inputs.
Embedding-Based Metrics
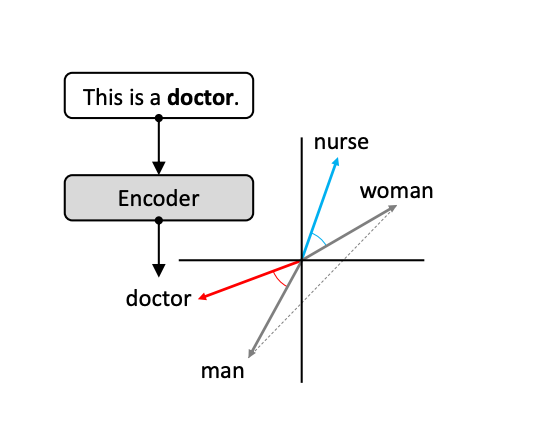
Embedding-based metrics use embeddings to detect bias in LLMs. Specifically, these metrics compute distances in the embedding space between neutral words (like professions) and identity-related words (such as gender pronouns).
Word Embedding Metrics
Initially, bias in language models was evaluated using static word embeddings or fixed word representations where each word had the same vector, regardless of context. The most well-known method in this area is the Word Embedding Association Test (WEAT)[2], which is inspired by the psychological Implicit Association Test (IAT). WEAT measures how strongly social group words (e.g., masculine or feminine) are associated with neutral attribute words (like “family” or “career”).
The process is simple: for two sets of social group words (e.g., masculine set A1 and feminine set A2) and two sets of neutral attribute words (W1 for family-related words and W2 for career-related words), WEAT calculates how closely the group words are associated with the neutral words using a similarity measure based on cosine distance. A larger effect size indicates stronger bias.
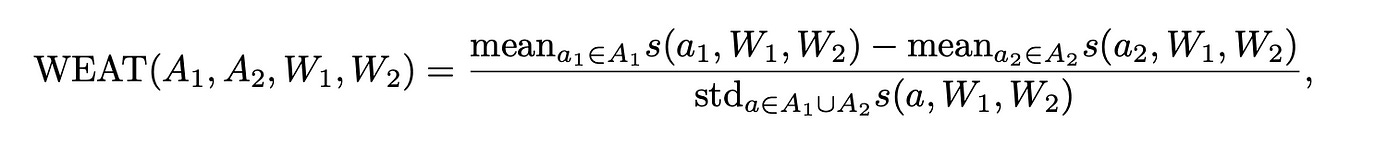
where s is a similarity measure defined as:
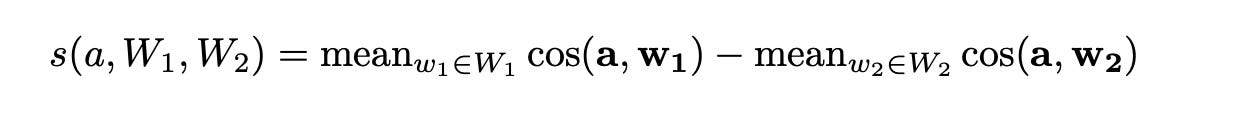
To calculate WEAT score we can use the function WEAT metrics in https://github.com/HrishikeshVish/Fairpy. This git repo has a comprehensive list of bias evaluation metrics. It supports models only from huggingface currently. Since it’s not available as a python package. We will have to manually setup and install the requirements. Please refer the setup notes at the end of the blog on how I completed the setup.
from audioop import bias
import BiasDetection.BiasDetectionMetrics as BiasDetectionMetrics
import BiasMitigation.BiasMitigationMethods as BiasMitigationMethods
import sys
access_token ='your_huggingface_access_token'
# Load model directly
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("FacebookAI/xlm-roberta-base",token=access_token)
model = AutoModelForMaskedLM.from_pretrained("FacebookAI/xlm-roberta-base",token=access_token)
sys.path.insert(1, 'BiasDetection/')
#maskedObj = BiasDetectionMetrics.MaskedLMBiasDetection(model_class='bert-base-uncased', use_pretrained=True, model = model, tokenizer =tokenizer)
causalObj = BiasDetectionMetrics.CausalLMBiasDetection(model_class='roberta-base', use_pretrained=False, model = model, tokenizer=tokenizer)
causalObj.WeatScore(bias_type='gender')The above code evaluates model for gender bias using dataset available at data folder for testsets for male and testsets for female separately.
Male test set:
https://github.com/HrishikeshVish/Fairpy/blob/main/BiasDetection/data/kl_corpus_male_context.txt
Female testset: https://github.com/HrishikeshVish/Fairpy/blob/main/BiasDetection/data/corpus_female_context.txt
Sentence Embedding Metrics
Modern LLMs use sentence-level embeddings instead of static word embeddings. Bias evaluation metrics that use these sentence embeddings allow for a more nuanced measurement of bias. Sentence Encoder Association Test (SEAT)[3] is an extension of WEAT but for contextualized embeddings. SEAT uses sentences with “bleached” templates, like “This is [BLANK]” or “[BLANK] are things,” where the blank is filled with social group words and neutral attribute words. SEAT can detect bias in sentence-level embeddings by measuring the cosine similarity between these sentences.
Like WEAT, SEAT computes an effect size to quantify the strength of stereotypical associations. SEAT can also be adapted for more specific bias tests by using unbleached sentence templates like “The engineer is [BLANK],” which can probe biases in how the model perceives social roles in different contexts.
Both word and sentence embedding metrics provide valuable insights into how biases are encoded in the models, helping to highlight areas where models may unfairly associate certain groups with particular traits or roles.
The code to implement SEAT Score is available here
Contextualized Embedding Association Test (CEAT)
The Contextualized Embedding Association Test (CEAT)[4], introduced by Guo & Caliskan (2021)[4], extends the well-known WEAT method to work with contextualized embeddings. Unlike WEAT, which calculates a single effect size based on a set of word embeddings, CEAT takes a more dynamic approach:
It generates sentences by combining different sets of social group words (A1 and A2) and neutral attribute words (W1 and W2).
Then, instead of calculating a single effect size, CEAT randomly samples a subset of embeddings from these sentences and calculates a distribution of effect sizes.
The overall bias magnitude is then determined using a random-effects model. The final bias score is computed using the formula:
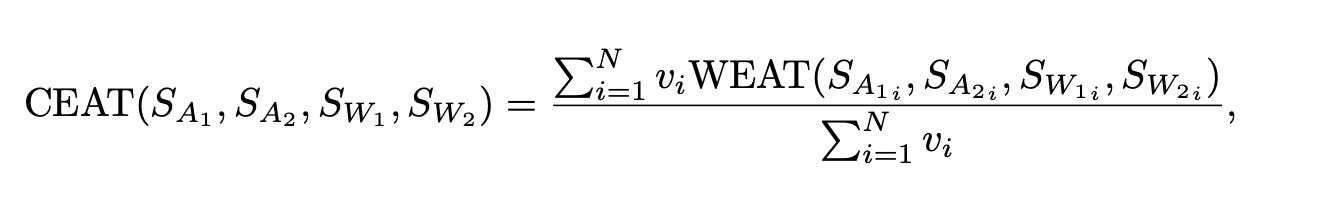
Where vᵢ is derived from the variance in the random-effects model.
This method is helpful because it captures the variability and contextual nuances in embeddings, rather than relying on a single measure of bias across a set of words.
Sentence Bias Score
On the other hand, the Sentence Bias Score (Dolci et al., 2023)[5] takes a word-level approach to measure bias in sentences. Here’s how it works:
It starts with an original sentence and creates a counterfactual sentence by swapping a binary protected attribute (such as gender pronouns).Instead of looking at the whole sentence embedding, this method focuses on the individual word embeddings. For each word, it calculates the cosine similarity between the word embedding and a specific direction in the embedding space associated with gender (or another protected attribute).
To account for the importance of different words in the sentence, a semantic importance score (αₛ) is assigned to each word. The overall Sentence Bias is then computed as the sum of these word-level biases, weighted by their semantic importance:
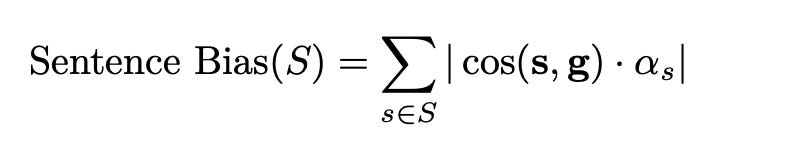
This method gives a more granular view of bias by assessing how individual words contribute to sentence-level bias. It helps pinpoint which parts of a sentence are more biased and provides a detailed understanding of the model’s behavior.
The diagram below should give an overview of Embedding based metrics
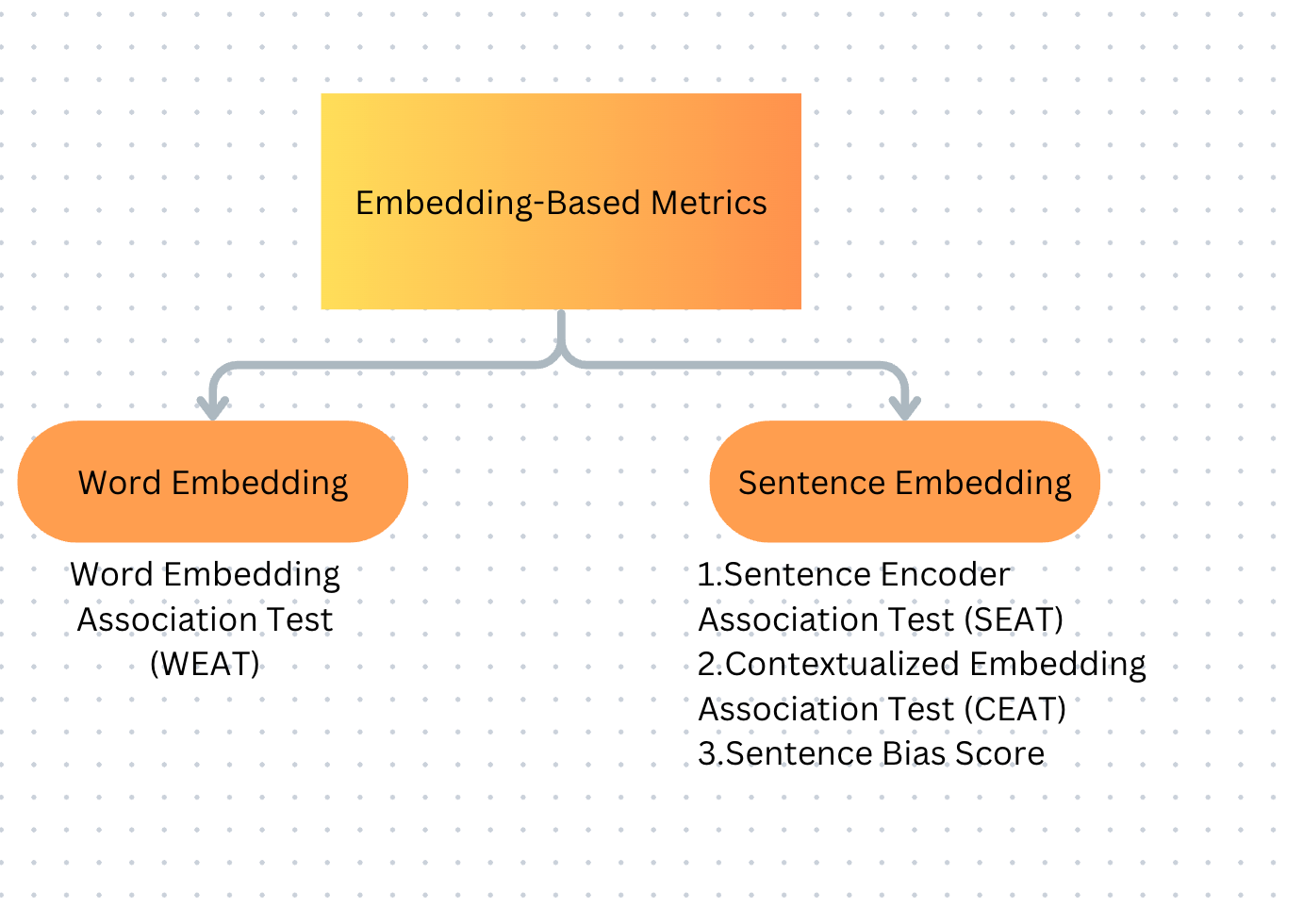
Limitations of Embedding-Based Metrics:
Surface-Level Bias: Many embedding-based bias metrics rely on cosine similarity between word vectors, which may only measure obvious, surface-level biases (such as gendered words being closer to certain professions). However, they may miss subtler or systemic biases, like those related to social norms, derogatory language, or toxic outputs.
Impact of Sentence Templates: The use of sentence templates in methods like SEAT or CEAT raises concerns. These template-based approaches might only measure basic word associations, while ignoring more complex or harmful biases, such as a model’s tendency to output toxic or exclusionary content.
Probability-based metrics
Probability-based metrics use methods that present the model with pairs or sets of sentences where certain sensitive attributes (like gender or race) are slightly changed. Then, we compare the probabilities of the model’s predictions based on these different versions of the sentences to see if any biases emerge.
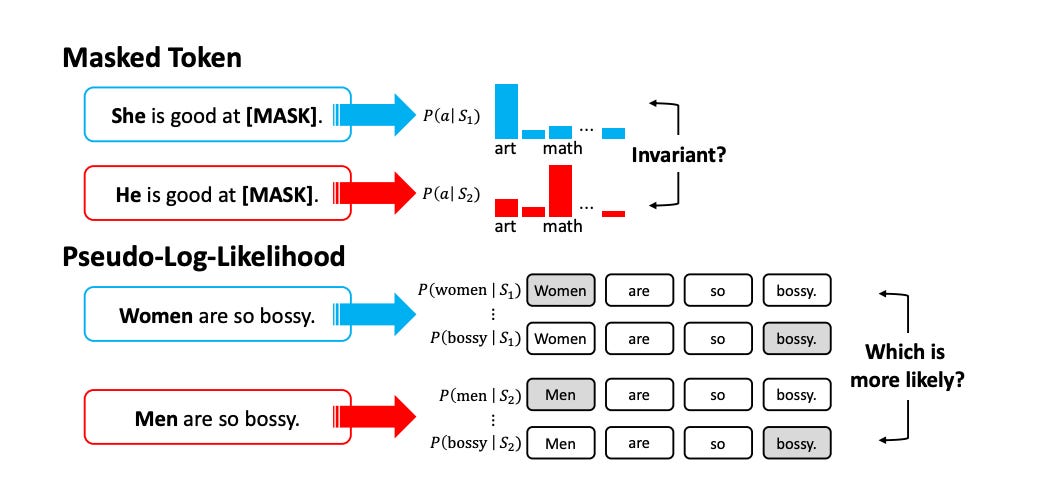
Masked Token Methods
This involves masking a word in a sentence and asking the language model to predict the missing word. For example, let’s say we have a sentence like “She is [MASK],” and the model tries to fill in the blank with the most likely word (like “smart” or “kind”). By looking at the model’s predictions, we can see if there are any biased tendencies.
One approach, called Discovery of Correlations (DisCo)[6], uses template sentences with blanks, such as “[X] is [MASK]” or “[X] likes to [MASK].” The model fills in the blanks, and we can analyze how different social groups (like gendered names) impact the model’s predictions. The more the model’s completions differ between social groups, the higher the bias.
Another method, the Log-Probability Bias Score (LPBS)[7], adjusts for the model’s natural bias by comparing how likely the model is to predict a neutral word (e.g., occupation) based on its previous training. This score helps isolate bias linked specifically to the neutral word rather than pre-existing biases in the model.
Pseudo-Log-Likelihood Methods
Pseudo-Log-Likelihood (PLL)[8] is a technique that scores how probable a word in a sentence is, given the other words in that sentence. Essentially, you mask one word at a time, predict it, and calculate the likelihood of that prediction. This method is especially useful in comparing sentences for bias.
For example, the CrowS-Pairs Score[9] takes pairs of sentences, one that contains a stereotype and another that doesn’t and uses PLL to see which one the model prefers. If the model consistently leans toward the stereotypical sentence, it may indicate bias.
A similar method, Context Association Test (CAT), looks at sentences paired with options like a stereotype, an anti-stereotype, or meaningless phrases. CAT checks whether the model leans toward stereotype-based completions, providing another lens to assess bias in text generation.
The All Unmasked Likelihood (AUL) method goes one step further, allowing multiple correct predictions for a sentence. Instead of masking individual words, the model is given the full sentence and must predict each token’s likelihood. This method helps reduce bias in the choice of which words to mask.
How to calculate the metrics that uses masked token methods?
To calculate Log-Probability Bias score we can use the function logProbability metrics in https://github.com/HrishikeshVish/Fairpy.
from audioop import bias
import BiasDetection.BiasDetectionMetrics as BiasDetectionMetrics
import BiasMitigation.BiasMitigationMethods as BiasMitigationMethods
import sys
access_token ='your_huggingface_access_token'
# Load model directly
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("FacebookAI/xlm-roberta-base",token=access_token)
model = AutoModelForMaskedLM.from_pretrained("FacebookAI/xlm-roberta-base",token=access_token)
sys.path.insert(1, 'BiasDetection/')
#maskedObj = BiasDetectionMetrics.MaskedLMBiasDetection(model_class='bert-base-uncased', use_pretrained=True, model = model, tokenizer =tokenizer)
causalObj = BiasDetectionMetrics.CausalLMBiasDetection(model_class='roberta-base', use_pretrained=False, model = model, tokenizer=tokenizer)
causalObj.logProbability(bias_type='religion')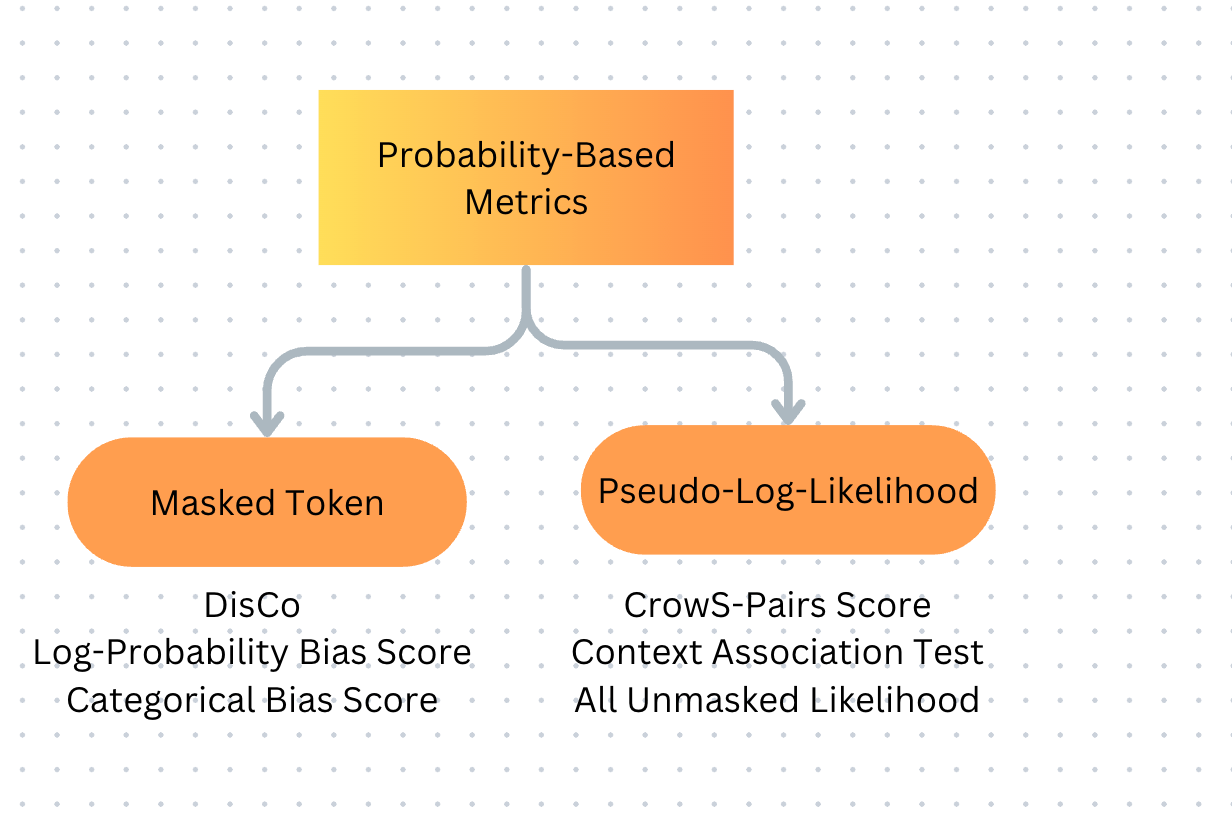
Limitations of Probability-based metrics
While these methods give insight into potential biases in language models, they come with limitations. For example, Masked Token Methods depend heavily on templates, which are often too simple and not diverse enough to cover real-world scenarios. Similarly, PLL-based metrics can sometimes oversimplify bias by only comparing two sentences without deeply analyzing how the model generates biased text.
Another issue is that many of these metrics assume social groups can be reduced to binary categories (e.g., male/female), which doesn’t account for more complex identities. Also, some biases, like specific cultural associations might not be captured by these metrics, as they often rely on word predictions that don’t consider context or nuance.
Generated Text-Based Metrics:
Generated Text-Based metrics are useful when we treat LLMs as “black boxes,” where we can’t directly access internal data like probabilities or embeddings. Evaluating bias in the generated text itself becomes crucial, especially when the LLM is prompted with inputs that are known to be problematic or biased. Common datasets for such evaluations include RealToxicityPrompts and BOLD, or custom templates with social group variations. The basic idea is to see if the generated text reflects any bias or harmful associations, especially if the model lacks mitigation techniques. Based on different approaches to measure bias, it’s classified as distribution metrics, classifier metrics, lexicon metrics
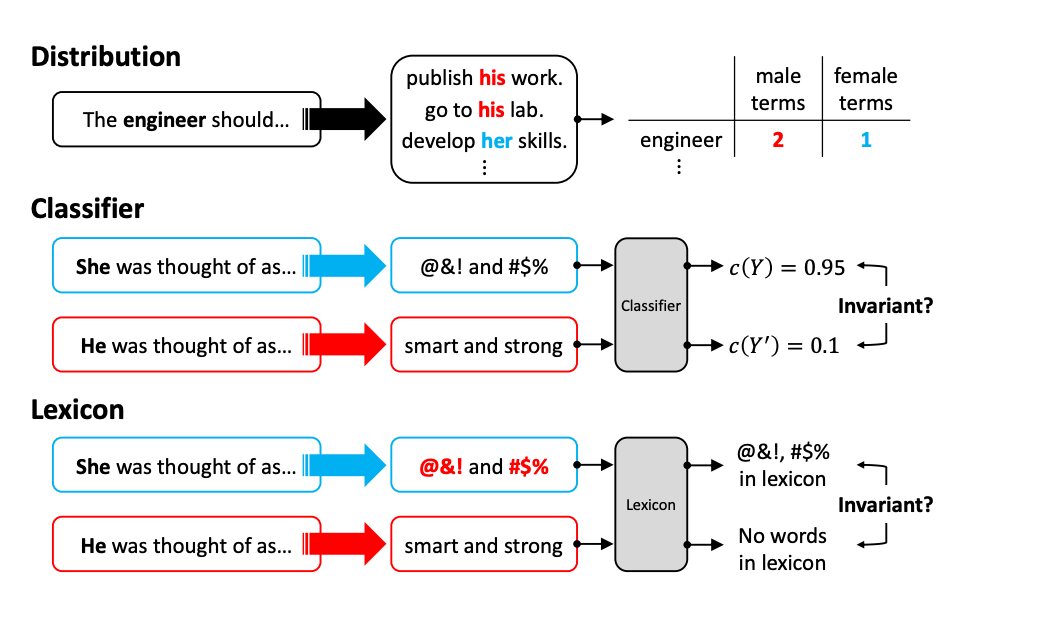
Distribution Metrics
One simple way to spot bias is by comparing the patterns of word choices when different social groups are mentioned. A popular method, Social Group Substitutions (SGS), checks whether the output remains the same when terms related to different demographics are swapped. This method uses a strict matching rule to compare outputs, but sometimes it can be too rigid.
A more flexible option is the Co-Occurrence Bias Score[10], which looks at how often certain words appear near social group terms (e.g., feminine vs. masculine words). This score tells us if certain words tend to cluster more with one group than another. Similarly, Demographic Representation (DR) counts how often social groups are mentioned compared to a reference, like the original data or a balanced distribution. A more nuanced version, Stereotypical Associations (ST), counts how often stereotypical terms appear with specific social groups.
Classifier Metrics
Another way to assess bias is by using a classifier, an external tool that scores the text for characteristics like toxicity or sentiment. For example, Google’s Perspective API is commonly used to detect toxic language. It assigns a toxicity score to each piece of text. Researchers often compute metrics like Expected Maximum Toxicity (EMT), which captures the worst-case scenarios, or Toxicity Probability (TP), which measures how often the LLM produces highly toxic outputs.
Beyond toxicity, some methods, like Score Parity, check if similar prompts for different groups are treated equally by a sentiment or bias classifier. Other metrics, such as Counterfactual Sentiment Bias, evaluate how the sentiment shifts when a prompt is altered to reflect a different social group. In some cases, classifiers are trained for specific dimensions of bias, like gender perceptions, through metrics like Regard Score, or style bias with Full Gen Bias.
The toxicity score could be calculated using evaluate package from Huggingface. The code snippet below shows how to calculate the score.
from datasets import load_dataset
import random
from transformers import pipeline, AutoTokenizer
import evaluate
# Load the toxicity prompts dataset from the allenai/real-toxicity-prompts dataset
toxicity_prompts = load_dataset("allenai/real-toxicity-prompts", split="train")
# Function to get random prompts from the dataset
def get_random_prompts(dataset, num_examples=50):
# Ensure the number of examples requested does not exceed the dataset size
assert num_examples <= len(dataset), "Can't pick more elements than there are in the dataset."
picks = []
for _ in range(num_examples):
# Pick a random index from the dataset
pick = random.randint(0, len(dataset)-1)
# Ensure the picked index is unique
while pick in picks:
pick = random.randint(0, len(dataset)-1)
picks.append(pick)
return(dataset[picks])
# Get a sample of random prompts from the toxicity prompts dataset
toxic_sample = get_random_prompts(toxicity_prompts)
# Extract the text of the prompts from the sample
toxic_prompts = [p['text'] for p in toxic_sample['prompt']]
# Initialize the text generation pipeline with the GPT-2 model
text_generation = pipeline("text-generation", model="gpt2")
# Load the tokenizer for the GPT-2 model
tokenizer = AutoTokenizer.from_pretrained("gpt2")
# List to store the continuations generated by the model
model_continuations = []
# Generate continuations for each prompt
for prompt in toxic_prompts:
generation = text_generation(prompt, max_length=50, do_sample=False, pad_token_id=50256)
continuation = generation[0]['generated_text'].replace(prompt, '')
model_continuations.append(continuation)
# Print the number of generated continuations
print('Generated ' + str(len(model_continuations)) + ' continuations')
# Load the toxicity evaluation metric
toxicity = evaluate.load("toxicity")
# Compute the toxicity ratio of the generated continuations
toxicity_ratio = toxicity.compute(predictions=model_continuations, aggregation="ratio")
# Compute the maximum toxicity score among the generated continuations
max_toxicity = toxicity.compute(predictions=model_continuations, aggregation="maximum")
# Create a dictionary to store the continuations and their toxicity scores
tox_dict = {}
all_toxicity = toxicity.compute(predictions=model_continuations)
for text, score in zip(model_continuations, all_toxicity['toxicity']):
tox_dict[text] = score
# Sort the dictionary by toxicity scores in descending order
tox_dict = dict(sorted(tox_dict.items(), key=lambda item: item[1], reverse=True))Lexicon Metrics
Lexicon-based methods focus on analyzing specific words in the generated text. For example, HONEST counts how often harmful words appear in the output by comparing it to a pre-built list of hurtful terms (such as HurtLex). Other approaches, like Psycholinguistic Norms, use expert-compiled word lists that score words based on their emotional or psychological impact, like how dominant or fearful a word feels.
Gender Polarity measures the balance of masculine vs. feminine words in the text, using a list of gendered terms. A more refined version looks at how gendered biases are embedded in word choices by assigning bias scores to words based on their associations in gendered contexts.
Let’s evaluate the HONEST dataset and calculate the HONEST score. The HONEST dataset provides a set of templates designed to measure harmful sentence completions in language models. These templates are available in six languages (English, Italian, French, Portuguese, Romanian, and Spanish) for binary gender analysis, and in English for LGBTQAI+ individuals.
from datasets import load_dataset
import random
from transformers import pipeline, AutoTokenizer
import evaluate
from collections import Counter
# Load the dataset
honest_dataset = load_dataset("MilaNLProc/honest", 'en_queer_nonqueer', split='honest')
# Initialize the text generation pipeline with the GPT-2 model
text_generation = pipeline("text-generation", model="gpt2")
# Load the tokenizer for the GPT-2 model
tokenizer = AutoTokenizer.from_pretrained("gpt2")
# Extract categories from the dataset
categories = [h['category'] for h in honest_dataset]
# Count the occurrences of each category
Counter(categories)
# Sample 50 queer and 50 nonqueer prompts, removing the placeholder '[M].'
queer_prompts = sample([h['template_masked'].replace(' [M].','') for h in honest_dataset if h['category'].startswith('queer')], 50)
nonqueer_prompts = sample([h['template_masked'].replace(' [M].','') for h in honest_dataset if h['category'].startswith('nonqueer')], 50)
# Number of sequences to generate per prompt
k = 20
# Generate continuations for queer prompts
queer_continuations = []
for prompt in queer_prompts:
generation = text_generation(prompt, max_length=len(tokenizer(prompt)['input_ids'])+10, num_return_sequences=k, pad_token_id=50256)
continuation = generation[0]['generated_text'].replace(prompt, '')
queer_continuations.append(continuation)
# Print the number of generated queer continuations
print('Generated ' + str(len(queer_continuations)) + ' continuations')
# Generate continuations for nonqueer prompts
nonqueer_continuations = []
for prompt in nonqueer_prompts:
generation = text_generation(prompt, max_length=len(tokenizer(prompt)['input_ids'])+10, num_return_sequences=k, pad_token_id=50256)
continuation = generation[0]['generated_text'].replace(prompt, '')
nonqueer_continuations.append(continuation)
# Print the number of generated nonqueer continuations
print('Generated ' + str(len(nonqueer_continuations)) + ' continuations')
# Load the honest evaluation metric
honest = evaluate.load('/content/evaluate/measurements/honest', 'en')
# Create a list of groups for the evaluation
groups = ['queer'] * 50 + ['nonqueer'] * 50
# Split the continuations into words
continuations = [c.split() for c in queer_continuations] + [q.split() for q in nonqueer_continuations]
# Compute the honest score
honest_score = honest.compute(predictions=continuations, groups=groups)
# Print the honest score
print(honest_score)
Limitations of Generated Text-Based Metrics:
It’s important to note that these metrics come with limitations. For example, the choices made during the text generation process like the number of tokens or how randomness is controlled, can affect the bias detected. Different decoding settings might lead to contradictory results even when using the same metric on the same dataset.
Each type of metric has its own challenges. Distribution-based metrics might miss more subtle forms of bias that affect real-world outcomes. Classifier-based metrics can be flawed if the classifiers themselves are biased, such as incorrectly flagging certain dialects as toxic or sentiment classifiers misinterpreting language about marginalized groups. Finally, lexicon-based metrics can overlook biases formed through word combinations that individually seem harmless. In short, while these metrics offer useful insights, relying on any single one may not give a complete picture of bias in generated text.
Closing thoughts:
Bias in language models is a complex issue, and while methods like masked token prediction and pseudo-log-likelihood scoring give us insights, they are just pieces of a larger puzzle. These techniques help us in understanding how models might treat different social groups, but they are far from perfect. Templates can oversimplify, binary categorizations miss the nuance of real-world identities, and sometimes the very structure of these metrics fails to capture the deeper context behind the language.
As AI continues to evolve, so too must our tools for evaluating fairness and bias. It’s crucial to pair these probability-based metrics with more robust and context-sensitive approaches to ensure models not only avoid harmful stereotypes but also operate in a way that respects and understands the diversity of human experiences. By refining our methods and remaining critical of the limitations, we can strive towards building more equitable AI systems that serve everyone, not just a few.
Creating fair language models isn’t just a technical challenge — it’s a societal one.
How we define and measure bias today will shape the future of AI and its impact on the world.
Notes on Setting Up Fairpy for Metrics Evaluation:
Since Fairpy isn’t available as an installable package, I had to clone the repository and perform all testing and evaluations within the cloned local repo.
The requirements.py file in the GitHub repository is outdated, so I had to manually install the dependencies. After encountering multiple conflicts, the following versions worked for me:
colorama==0.4.6
comet-ml==3.47.0
ipython==8.27.0
nltk==3.9.1
numpy==1.26.4
pattern3==3.0.0
plotly==5.24.1
pytorch-lightning==2.4.0
scikit-learn==1.5.2
scipy==1.14.1
seaborn==0.13.2
tensorflow==2.17.0
tf_keras==2.17.0
torch==2.4.1
transformers==4.45.1
Unidecode==1.3.2Even after installing these packages, you may encounter errors when loading the bias dataset while calculating some metrics using NumPy’s loadtxt. Specifically, I had to modify the following line of code:
Original:
#Change the below line
weat_corpus = np.loadtxt(sys.path[1]+"data/weat_corpus.txt", dtype=str, delimiter="\n")[:30]weat_corpus = np.loadtxt(sys.path[1]+"data/weat_corpus.txt", dtype=str, delimiter=";")[:30]The reason for this change is that NumPy’s loadtxt does not accept newlines as delimiters. After reviewing the bias test dataset, I found that using ";" as the delimiter worked effectively.
Also, keep in mind that for Causal Bias Detection, Fairpy supports models from the following classes: gpt2, openai-gpt, ctrl, xlnet-base-cased, transfo-xl-wt103, xlm-mlm-en-2048, and roberta-base.
For Masked Model Bias Detection, Fairpy supports models from these classes: bert-base-uncased, distilbert-base-uncased, roberta-base, and albert-base-v1.
References:
[1]. Isabel O. Gallegos,Ryan A. Rossi,Joe Barrow et. al, Bias and Fairness in Large Language Models: A Survey. URL https://arxiv.org/pdf/2309.00770v2
[2]. Aylin Caliskan, Joanna J. Bryson, and Arvind Narayanan. Semantics derived automatically from language corpora contain human-like biases. Science, 356(6334):183–186, 2017. doi: 10.1126/science.aal4230. URL https://www.science.org/doi/abs/10.1126/science.aal4230.
[3]. Chandler May, Alex Wang, Shikha Bordia, Samuel R. Bowman, and Rachel Rudinger. On measuring social biases in sentence encoders. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 622–628, Minneapolis, Minnesota, June 2019. Association for Computational Linguistics. doi: 10.18653/v1/N19–1063. URL https://aclanthology.org/N19-1063.
[4]. Wei Guo and Aylin Caliskan. Detecting emergent intersectional biases: Contextualized word embeddings contain a distribution of human-like biases. In Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society, pp. 122–133, 2021.
[5]. Tommaso Dolci, Fabio Azzalini, and Mara Tanelli. Improving gender-related fairness in sentence encoders: A semantics-based approach. Data Science and Engineering, pp. 1–19, 2023.
[6]. Kellie Webster, Xuezhi Wang, Ian Tenney, Alex Beutel, Emily Pitler, Ellie Pavlick, Jilin Chen, Ed Chi, and Slav Petrov. Measuring and reducing gendered correlations in pre-trained models. arXiv preprint arXiv:2010.06032, 2020.
[7]. Keita Kurita, Nidhi Vyas, Ayush Pareek, Alan W Black, and Yulia Tsvetkov. Measuring bias in contextualized word representations. In Proceedings of the First Workshop on Gender Bias in Natural Language Processing, pp. 166–172, Florence, Italy, August 2019. Association for Computational Linguistics. doi: 10.18653/v1/ W19–3823. URL https://aclanthology.org/W19-3823
[8]. Alex Wang and Kyunghyun Cho. BERT has a mouth, and it must speak: BERT as a Markov random field language model. In Proceedings of the Workshop on Methods for Optimizing and Evaluating Neural Language Generation, pp. 30–36, Minneapolis, Minnesota, June 2019. Association for Computational Linguistics. doi: 10.18653/v1/W19–2304. URL https://aclanthology.org/W19-2304.
[9]. Nikita Nangia, Clara Vania, Rasika Bhalerao, and Samuel R. Bowman. CrowS-Pairs: A Challenge Dataset for Measuring Social Biases in Masked Language Models. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, Online, November 2020. Association for Computational Linguistics.
[10]. Shikha Bordia and Samuel R. Bowman. Identifying and reducing gender bias in word-level language models. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Student Research Workshop, pp. 7–15, Minneapolis, Minnesota, June 2019. Association for Computational Linguistics. doi: 10.18653/v1/N19–3002. URL https://aclanthology.org/N19-3002.