
How to detect Hallucinations in LLM?
A deep dive into methodologies to detect LLM Hallucinations

It is highly critical that LLM’s responses are trustworthy for it to be useful, and hence detecting hallucinations is very important. Traditional methods, which uses word overlap, are not good at spotting the subtle differences between accurate content and hallucinations. Hence we need an advanced techniques specifically designed to detect hallucinations in LLMs.
And, different detection strategies are needed because of the varied nature of Hallucinations. In this blog we will explore some main ways to detecting hallucinations, focusing on two types of hallucination, factuality hallucinations and faithfulness hallucinations.
Detecting Factuality Hallucinations
First let’s try to understand what it is.
What is Factuality Hallucinations?
When AI Models Get Facts Wrong while answering it’s called Factuality Hallucination
Factuality hallucinations in Large Language Models (LLMs) refer to instances where AI systems generate information that is factually incorrect or unsupported by real-world evidence. Factuality hallucinations occur when Large Language Models (LLMs) produce content that:
Contains statements that are false when compared to verified facts
Invents non-existent information, events, or entities
Misattributes information or quotes
Presents speculative or imaginary scenarios as factual
Combines true and false information in a way that creates a misleading narrative
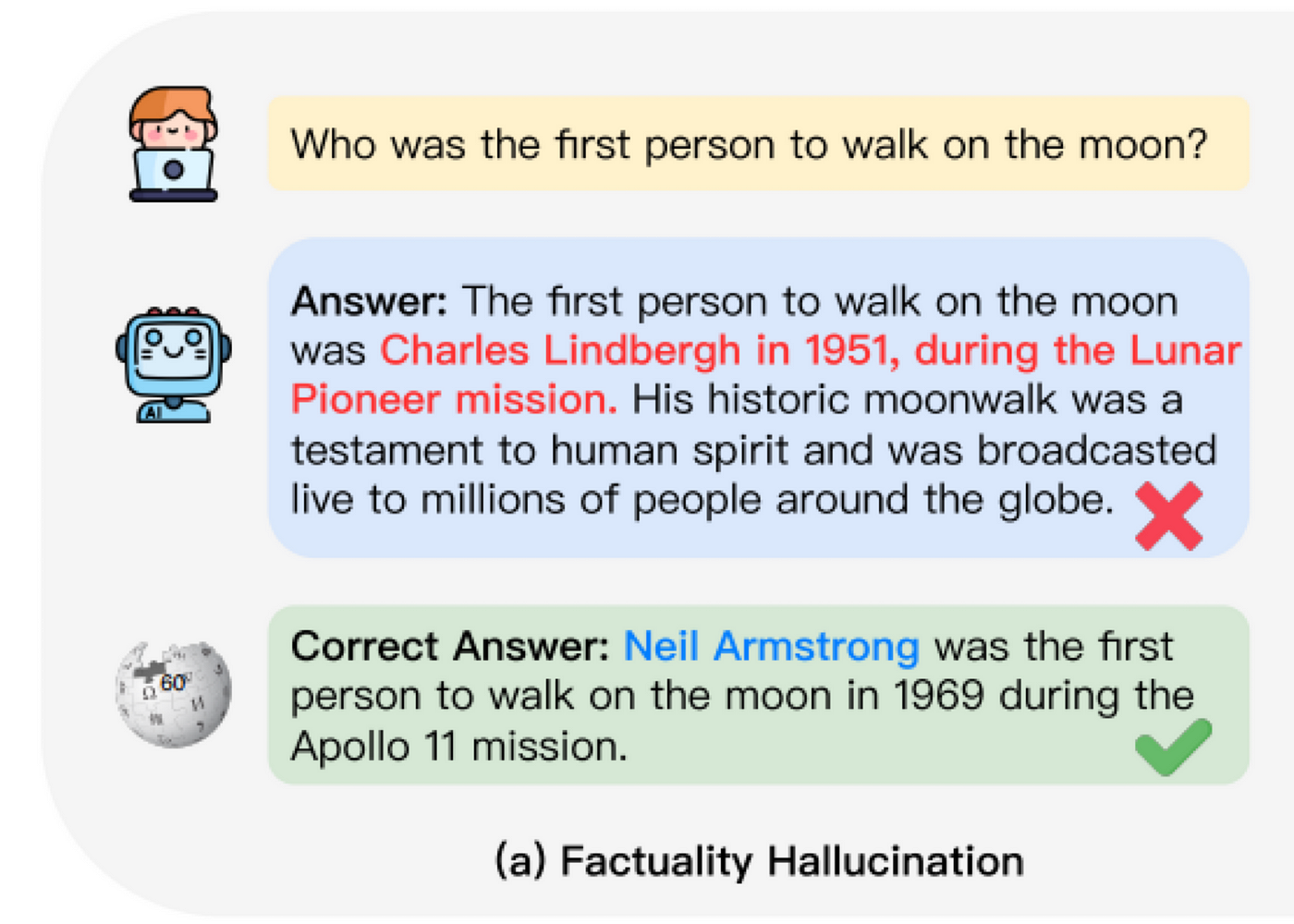
There are two main types of factuality hallucinations: Factual inconsistency and Factual fabrication
Factual inconsistency occurs when LLM provides information that contains elements of truth but misapplies or misaligns these facts. It typically involves confusing related but distinct events, people, or concepts, resulting in responses that seem plausible but are incorrect when closely examined. This type of error highlights the challenge of developing AI that cannot only recall information but also accurately contextualize and apply it. Refer Table 1 below for an example of the same.
Factual fabrication occurs when an AI model generates information that is entirely fictitious or unverifiable, often presenting it as truthful. This phenomenon typically arises when the model is prompted about topics with no factual basis, leading it to create plausible-sounding but invented details. Such errors stem from the AI’s training process and its attempt to produce coherent responses even when faced with queries that lack grounded, factual answers. Refer Table 1. below for an example of the same.

Research by Chen and Shu (2023)[2] has shown that even humans struggle to identify misinformation generated by models like ChatGPT. This difficulty has sparked an interest in developing methods to detect factuality hallucinations. The two main approaches are:
Retrieving External Facts: Comparing the model’s output with external sources of truth.
Uncertainty Estimation: Assessing how confident the model is in the information it generates.
Retrieving External Facts
To identify factual errors in content generated by large language models (LLMs), a straightforward approach is to compare the generated information with trusted knowledge sources. This method is similar to traditional fact-checking but often needs to be adapted for real-world scenarios, which can be more complex.

Recent advancements focus on improving this process:
Automated Fact-Checking: Chen et al. (2023c) developed an automated system that breaks down claims, retrieves relevant documents, summarizes them, and checks their accuracy.
Resolving Conflicting Information: Galitsky (2023) suggested a method to resolve conflicting evidence by prioritizing the most reliable sources.
FACTSCORE Metric: Min et al. (2023) introduced a metric called FACTSCORE, which breaks down long text into smaller facts and checks how many of them are supported by reliable sources.
Enhanced Retrieval Techniques: Huo et al. (2023) improved the retrieval of supporting evidence by combining the original question with the LLM-generated answer, ensuring that the retrieved information is relevant and accurate.
Unified Framework: Chern et al. (2023) proposed a framework that uses various external tools to help LLMs detect factual errors.
Uncertainty Estimation
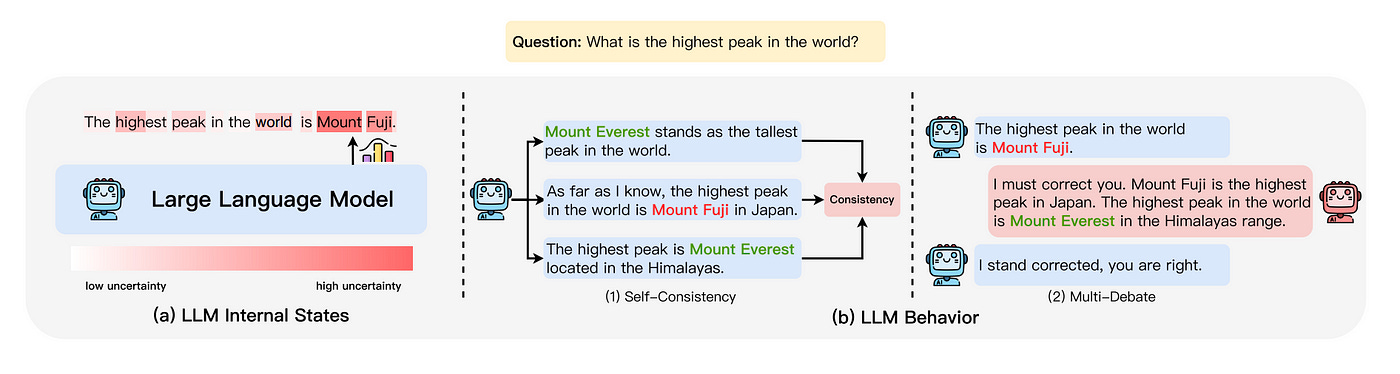
Uncertainty Estimation is a key method to detect hallucinations in Large Language Models (LLMs), especially when external fact-checking isn’t an option. The idea is that LLMs tend to generate hallucinations when they are uncertain. By measuring this uncertainty, we can identify when the model might be hallucinating.
There are two main approaches to this:
LLM Internal States: This approach looks at the model’s internal workings, like the probability it assigns to each word or token it generates.
Key Techniques:
Token Probability: If the model assigns a very low probability to certain key concepts, it likely means it’s uncertain about them.
Self-Evaluation: The model is asked to explain a concept and then recreate it based on its explanation. The better it can do this, the more confident it is in the concept.
Adversarial Attacks: By intentionally trying to trick the model into making errors, researchers can observe how uncertain the model is and set thresholds to detect hallucinations.
2. LLM Behavior: When internal states aren’t accessible (like when using APIs), researchers focus on the model’s outward behavior.
Key Techniques:
Consistency Checking: By asking the model the same question multiple times and checking if the answers are consistent, we can gauge its uncertainty.
Indirect Queries: Instead of directly asking for information, indirect questions are used to see how the model handles uncertainty.
Multi-Model Interrogation: Using one model to question another (like a legal cross-examination) to spot inconsistencies in the generated content.
Faithfulness Hallucination Detection
First things first,
What is Factuality Hallucinations?
Factuality hallucinations occurs when AI Models Don’t Follow Instructions
Faithfulness hallucinations occur when Large Language Models (LLMs) generate content that:
Deviates from or isn’t supported by the given input, context, or source material
Adds extraneous information not present in the original prompt or data
Misinterprets or incorrectly paraphrases the provided information
Omits crucial details from the source, altering the meaning or intent
Combines information from the input with unrelated knowledge in a way that misrepresents the original content

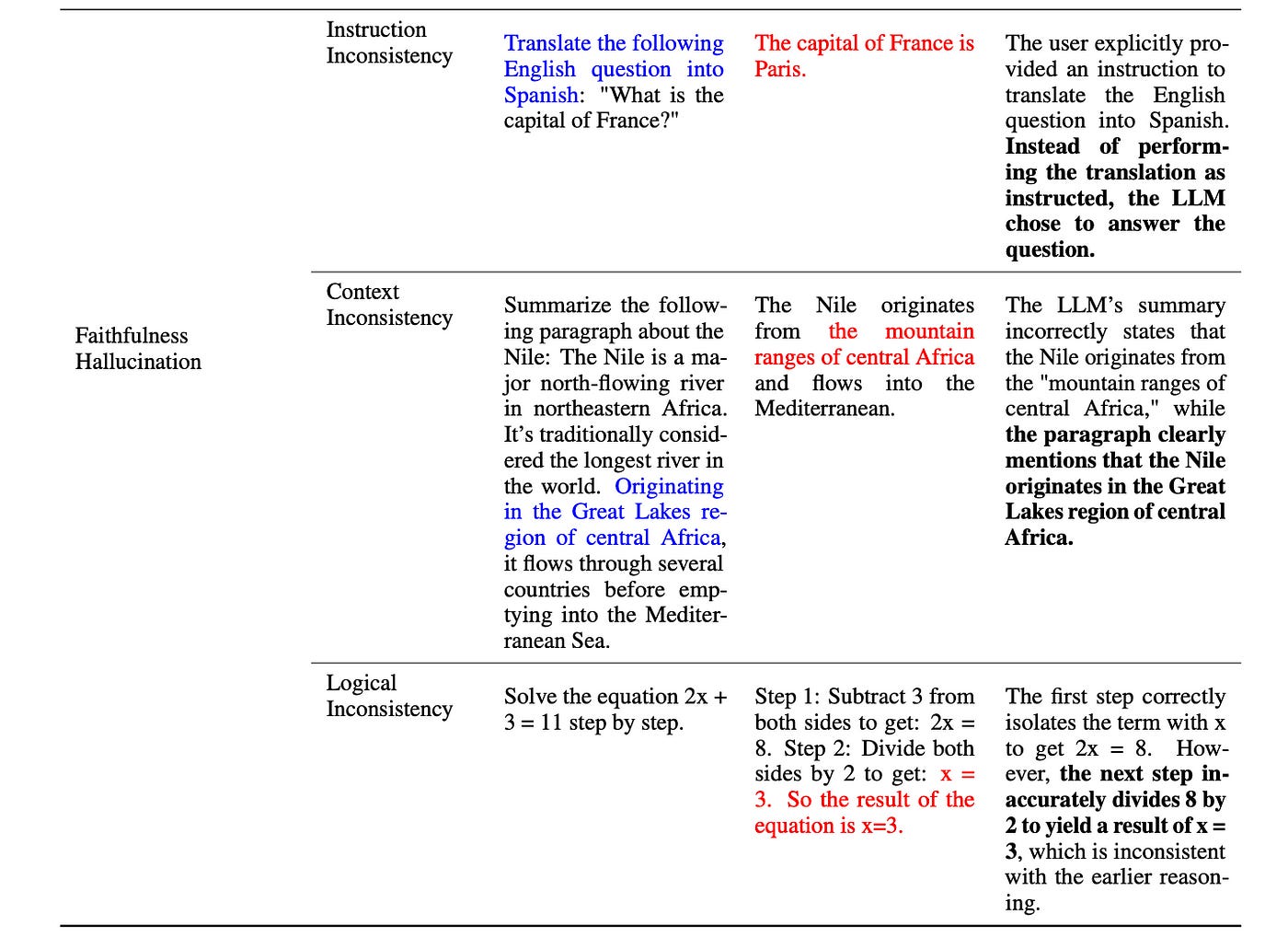
We call these mistakes “faithfulness hallucinations”. There are three types of faithfulness hallucinations:Instruction Inconsistency, Context Inconsistency, Logical Inconsistency
Instruction Inconsistency:
Instruction inconsistency occurs when an AI model fails to adhere to or misinterprets the user’s explicit instructions. This error manifests as responses that deviate from the requested task or format, demonstrating a failure to accurately process or act upon the given directives.
Context Inconsistency:
Context inconsistency arises when an AI model’s output contradicts or disregards the contextual information provided by the user. This type of error shows a lack of alignment between the model’s response and the specific background or situational details given, resulting in irrelevant or contradictory information.
Logical Inconsistency:
Logical inconsistency emerges when an AI model’s output contains internal contradictions or flawed reasoning, despite potentially correct individual elements. This error type is characterized by responses that may seem partially correct but fail to maintain coherence or arrive at logically sound conclusions when considered as a whole.
It is important and crucial that LLMs stay faithful to the given context or user instructions, especially in tasks like summarization or interactive dialogue. Faithfulness hallucination detection is about making sure the model’s output aligns with the provided context without adding irrelevant or contradictory information. Here’s a look at how unfaithfulness in LLM outputs can be detected.
1. Fact-Based Metrics
One of the most straightforward ways to assess faithfulness is by checking how well the key facts in the generated content match the source content.
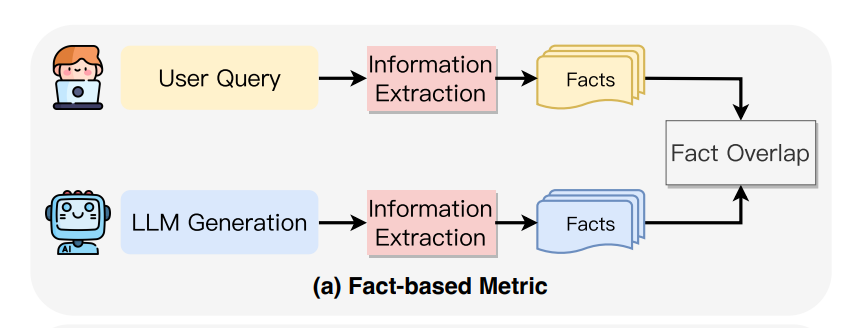
There are different methods for doing this, based on what types of facts are being compared:
N-gram Based Metrics:
N-gram based metrics like ROUGE and PARENT-T, measure the overlap of word sequences (n-grams) between the generated content and the source. However, they often fall short because they depend on surface-level matching and don’t always align well with human judgment.
Entity-Based Metrics:
In summarization tasks, the accuracy of key entities (people, places, things) is critical. If a model fails to accurately reproduce these entities, the summary is considered unfaithful. Nan et al. (2021) developed a metric that measures how well the generated entities match those in the source content.
Relation-Based Metrics:
Even if the entities are correct, the relationships between them might be wrong. Goodrich et al. (2019) introduced a metric that checks the accuracy of these relationships by comparing relation tuples (pairs of related entities) in the generated content with those in the source.
Knowledge-Based Metrics:
In knowledge-grounded tasks, the model’s output should align with the knowledge provided in the context. The Knowledge F1 metric, introduced by Shuster et al. (2021), measures how well the generated content reflects the supplied knowledge.
Classifier-Based Metrics:
Classifier-based metrics offer a more direct approach to assessing the faithfulness of content generated by large language models (LLMs). These metrics use classifiers trained on datasets that include both hallucinated and faithful content, as well as data from related tasks or synthetically generated data.
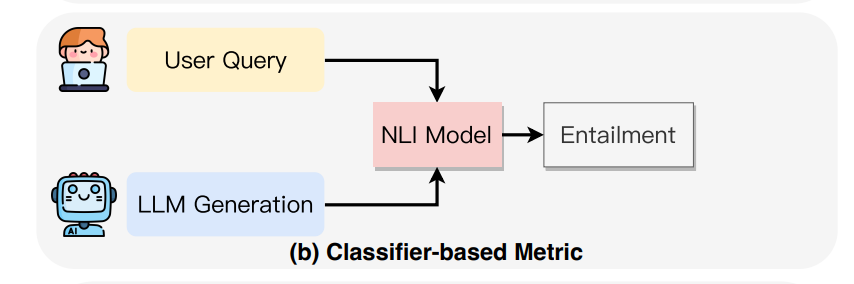
The two main categories are entailment-based and weakly supervised methods.
1. Entailment-Based Metrics
These metrics are built on the concept of Natural Language Inference (NLI), where the idea is that if the generated content is faithful, it should be logically supported by its source content. Key points include:
NLI Classifiers: Classifiers trained on NLI datasets can help identify factual inaccuracies, particularly in abstract summarization. However, there’s a challenge due to the mismatch in the level of detail between standard NLI datasets and the specific inconsistencies found in generated text.
Advanced Methods: To improve detection accuracy:
Adversarial Fine-Tuning: Classifiers are fine-tuned on more challenging datasets that include tricky, adversarial examples.
Dependency Arc Analysis: Breaking down entailment at the level of relationships between words (dependency arcs) provides a more detailed analysis.
Sentence Pair Scoring: Documents are split into sentences, and the consistency between these sentence pairs is analyzed.
2. Weakly Supervised Metrics
Weakly supervised methods are used when there’s a lack of annotated data. These methods leverage related tasks or generate synthetic data to train classifiers:
Rule-Based Transformations: Kryscinski et al. (2020) developed weakly supervised data by analyzing errors in summarization models and applying rule-based transformations to fine-tune classifiers.
Token-Level Detection: Zhou et al. (2021) created methods to automatically generate data that can detect hallucinations at the token level (individual words or phrases).
Adversarial Synthetic Data: Dziri et al. (2021b) used adversarial techniques to generate synthetic data, which helps improve hallucination detection in dialogue systems.
Factual Consistency in Conversations: Santhanam et al. (2021) focused on ensuring factual consistency within conversational AI models.
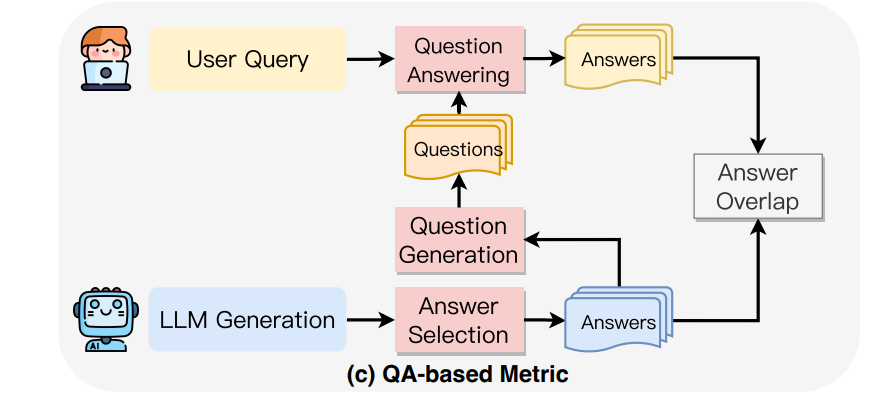
Question-Answering (QA) Based Metrics:
QA-based metrics have gained attention for their effectiveness in evaluating how well the content generated by a model aligns with its source information. Here’s how they work:
How It Works:
First, key pieces of information (target answers) are identified from the model’s output.
Questions are then generated based on these target answers.
These questions are used to extract corresponding answers (source answers) from the original content or user context.
Finally, the faithfulness of the model’s output is evaluated by comparing how well the source and target answers match.
Uncertainty Estimation
Uncertainty estimation helps identify when a model is likely to generate hallucinated content by measuring how uncertain the model is about its predictions. This concept is rooted in Bayesian deep learning, where uncertainty is often represented by the predictive entropy (a measure of randomness) in the model’s output.
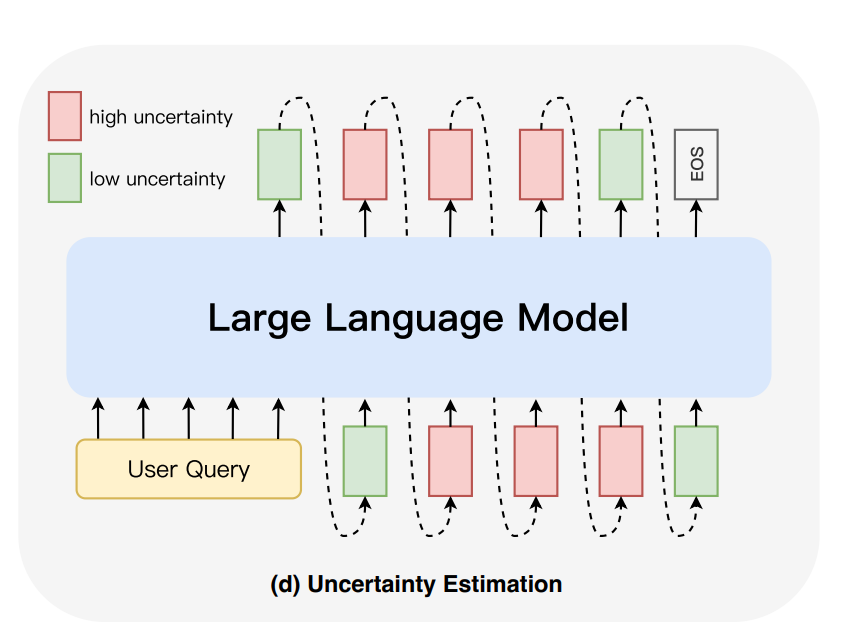
Types of Uncertainty Estimation:
Entropy-Based:
Deep Ensembles: Xiao and Wang (2021) found that higher uncertainty (measured by deep ensembles) correlates with a higher likelihood of hallucinations in data-to-text generation.
Monte Carlo Dropout: Guerreiro et al. (2023a) used the variation in predictions generated by Monte Carlo Dropout as an uncertainty measure in neural machine translation.
Conditional Entropy: Van der Poel et al. (2022) applied conditional entropy to assess uncertainty in abstractive summarization.
2.`Log-Probability-Based:
Guerreiro et al. (2023a) also used log-probability, normalized by the length of the sequence, to gauge how confident the model is in its output.
3. Model-Based:
SelfCheck: Miao et al. (2023) developed a system called SelfCheck for complex reasoning tasks. It evaluates each reasoning step by extracting targets, gathering information, regenerating steps, and comparing results to aggregate confidence scores. This method enhances the accuracy of question-answering by closely monitoring the model’s reasoning process.
Prompting-Based Metrics
Prompting-Based Metrics leverage the strong instruction-following abilities of large language models (LLMs) to automatically assess the accuracy and reliability of their own generated content.
How It Works:
Researchers provide LLMs with specific evaluation guidelines and input both the model-generated content and the original source content.
The LLM then evaluates the faithfulness of the generated content based on the provided guidelines.
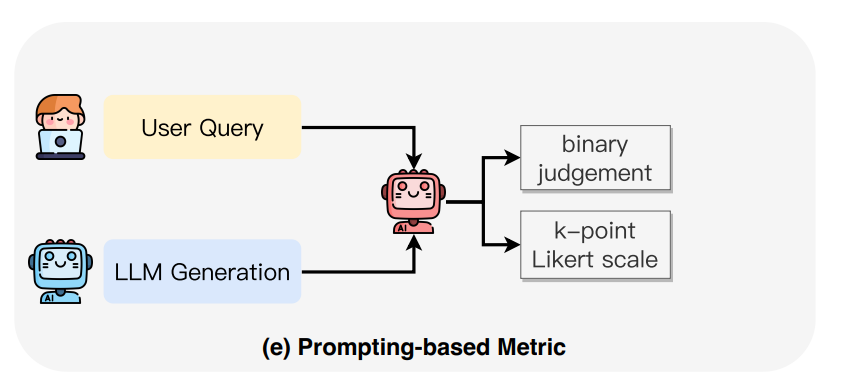
Output Formats:
The evaluation can result in a binary judgment (simply stating whether the content is faithful or not) or a more nuanced k-point Likert scale (rating the degree of faithfulness on a scale).
Types of Prompting:
Direct Prompting: Asking the model directly to evaluate the content.
Chain-of-Thought Prompting: Encouraging the model to think through the evaluation process step by step (Adlakha et al., 2023).
In-Context Learning: Providing examples in the prompt to guide the model on how to evaluate (Jain et al., 2023).
Explanatory Evaluation: Letting the model generate an evaluation along with an explanation of its reasoning (Laban et al., 2023).
References:
[1] A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions by Lei Huang et al. link to paper
[2] Hung-Ting Chen, Fangyuan Xu, Shane A Arora, and Eunsol Choi. 2023b. Understanding retrieval augmentation for long-form question answering. ArXiv preprint, abs/2310.12150.
[3] Jifan Chen, Grace Kim, Aniruddh Sriram, Greg Durrett, and Eunsol Choi. 2023c. Complex claim verification with evidence retrieved in the wild. ArXiv preprint, abs/2305.11859.
[4] Boris A Galitsky. 2023. Truth-o-meter: Collaborating with llm in fighting its hallucinations.
[5] Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Wei Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. 2023. Factscore: Fine-grained atomic evaluation of factual precision in long form text generation. ArXiv preprint, abs/2305.14251.
[6] Siqing Huo, Negar Arabzadeh, and Charles L. A. Clarke. 2023. Retrieving supporting evidence for llms generated answers. ArXiv preprint, abs/2306.13781.
[7] I Chern, Steffi Chern, Shiqi Chen, Weizhe Yuan, Kehua Feng, Chunting Zhou, Junxian He, Graham Neubig, Pengfei Liu, et al. 2023. Factool: Factuality detection in generative ai–a tool augmented framework for multi-task and multi-domain scenarios. ArXiv preprint, abs/2307.13528.
[8] Feng Nan, Ramesh Nallapati, Zhiguo Wang, Cicero Nogueira dos Santos, Henghui Zhu, Dejiao Zhang, Kathleen McKeown, and Bing Xiang. 2021. Entitylevel factual consistency of abstractive text summarization. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pages 2727–2733, Online. Association for Computational Linguistics.
[9] Ben Goodrich, Vinay Rao, Peter J. Liu, and Mohammad Saleh. 2019. Assessing the factual accuracy of generated text. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD 2019, Anchorage, AK, USA, August 4–8, 2019, pages 166–175. ACM.
[10] Kurt Shuster, Spencer Poff, Moya Chen, Douwe Kiela, and Jason Weston. 2021. Retrieval augmentation reduces hallucination in conversation. In Findings of the Association for Computational Linguistics: EMNLP 2021, pages 3784–3803, Punta Cana, Dominican Republic. Association for Computational Linguistics.