
Does AI-assisted Writing reduce Diversity?
Yes, they do reduce diversity, according to recent research.

Large language models (LLMs) like ChatGPT are revolutionizing how we create content. They help us write faster and with better quality and have become invaluable tools for many writers. But with the increasing reliance on these models, there’s a growing concern:
Are we sacrificing creativity for convenience?
It feels like everyone is writing from the same playbook. The articulation and flow might still be good, but all content is starting to feel the same. This is what researchers are calling an “algorithmic monoculture.” They have begun to question whether using the same LLMs(ChatGPT) makes our writing sound more alike, potentially dampening the individuality that makes content stand out.
A recent study examined this issue more closely. The researchers wondered if these language models, especially the ones fine-tuned with human feedback, might shrink the diversity of voices in the writing world. To find out, they asked people to write essays on hot topics from the New York Times, some with the help of GPT-3, others with a more fine-tuned model, InstructGPT, and some without any AI assistance.
The results were telling:
While InstructGPT helped people write more consistently, it also made their essays less diverse in vocabulary and more repetitive.
Interestingly, GPT-3 didn’t have quite the same effect, even though it contributed a significant portion of the writing. So, what does this mean for the future of writing and creativity? Let’s dive in to understand more about the research conducted.
Experiment design
The research employed a controlled experimental approach to examine the impact of large language models (LLMs) on content diversity. By controlling both the set of writers and the essay topics, the researchers aimed to compare essays written with and without assistance from language models.
Task Setup
Participants were asked to write argumentative essays on topics from the New York Times Student Opinion series, such as “What are the most important things students learn at school?”. Each essay was to be around 300 words, giving participants enough room for varied responses.
The CoAuthor platform, developed by Lee et al. (2022a), was used to conduct this experiment. When participants pressed the TAB key, they received five text suggestions from a backend model displayed in a dropdown menu. Writers could accept, edit, or reject these suggestions, though they must request at least five suggestions per essay.
The entire writing process, including keystrokes, suggestions, and user interactions, was recorded for analysis to determine which parts of the text were introduced by the writers versus the model.
Experiment Setup
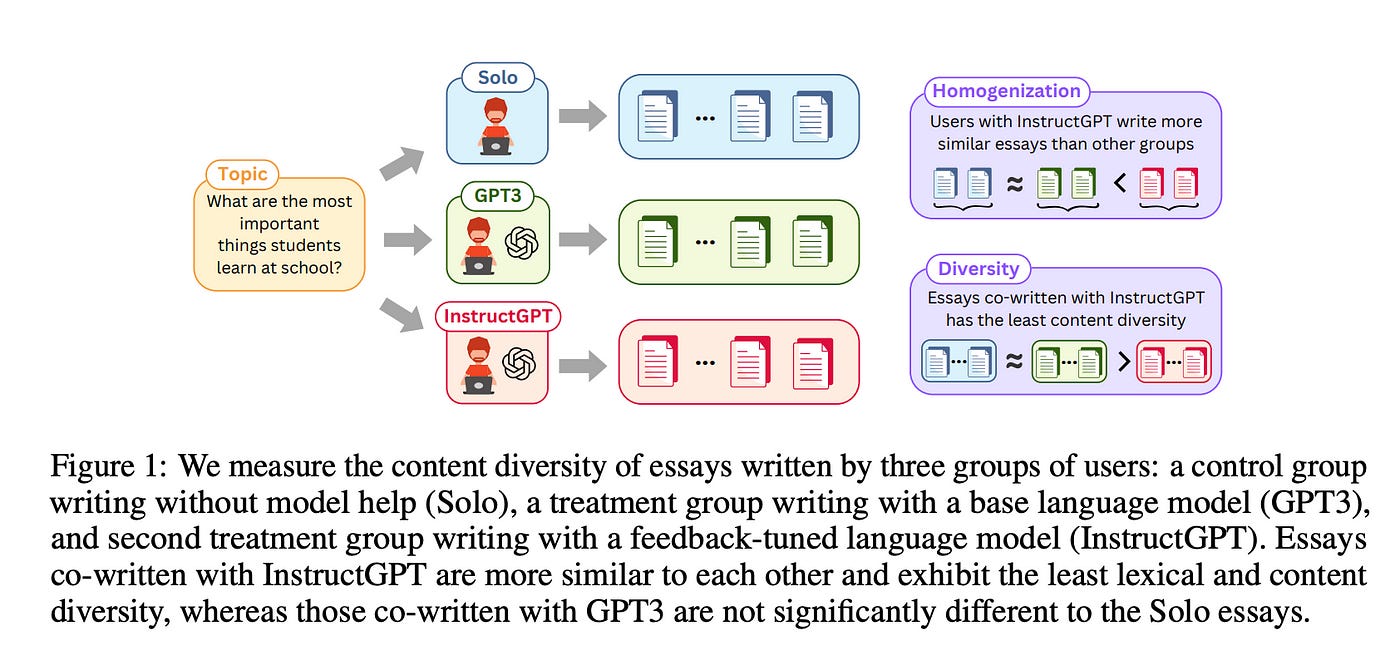
Participants for the study were recruited from Upwork, and all native English speakers had experience in writing or copyediting. Essays were collected in three different settings:
Solo — participants wrote without model assistance.
GPT-3 — participants wrote with the help of a base language model.
InstructGPT — participants wrote using a language model fine-tuned on human feedback.
Each participant was asked to write a 3–4 paragraph argumentative essay expressing their opinion on the given topic, with a target length of around 300 words. When using AI assistance, they were encouraged to request model suggestions at least five times to explore the effects of incorporating AI-generated text into their writing. The list of topics given to the participants is in the table below.

User Engagement with the Model
Before analyzing content diversity, the study assessed the level of collaboration between users and language models by examining how frequently users engaged with the model and how much of the final text was model-generated.
Usage Statistics
The results show that users actively engaged with the language models during their writing. On average, participants queried the model nine times per essay, accepting about 70% of the suggestions, which exceeds the required minimum of five queries.
Despite accepting suggestions, users often edited them before finalizing the essay. The platform recorded detailed keystroke data, tracking whether the model or the user introduced each character. On average, the model contributed 35% of the characters in each essay, indicating its usefulness in the writing process.

Interestingly, no significant difference was observed between the base GPT-3 model and the feedback-tuned InstructGPT on user engagement. Independent t-tests on the number of queries and acceptance rates showed no statistical significance at the 5% level, suggesting both models were equally helpful to users.
Model Contribution to Key Ideas
While the usage statistics highlight the frequency of model contributions, the study also explored whether the models contributed to key arguments or merely assisted with elaboration. To quantify the model’s contribution to core ideas, each essay was summarized into a list of critical points using GPT-3.5-turbo, which was then analyzed to determine the extent of model involvement in the main ideas.
Using the Rouge-L metric to get the critical points with corresponding sentences in the essay, the study attributed each key point to the model or the user based on the percentage of model-generated characters in the sentence. If the model generated more than half of a sentence’s characters, the key point was attributed to the model.
The analysis revealed that models contributed to approximately 40% of the key points across essays in the GPT-3 and InstructGPT groups. However, user reliance on the model varied widely, with some essays having none or all of the key points contributed by the model, indicating diverse levels of dependency on AI assistance.
Do LLMs Make Essays More Similar?
The following researchers tried to measure the homogenization of contents.
What is Homogenization?
Homogenization refers to how similar an essay is to other essays on the same topic.
Homogenization examines how closely an essay resembles other essays on the same topic. It’s measured by calculating the average similarity between an essay and all the others written on the same subject. They averaged these similarities across the entire set of essays to get an overall score.
Two metrics were used to measure this similarity: Rouge-L, which focuses on text overlap, and BertScore (Zhang et al., 2020), which compares the semantic similarity of the essays based on their embeddings. Both metrics produce scores between 0 and 1, with higher values indicating greater similarity.
Results
The study found that when writers used InstructGPT, their essays were much more alike than those written with GPT-3 or without AI assistance. The “homogenization” scores were significantly higher for InstructGPT, showing that essays became more similar in structure and language.
The Rouge-L and BertScore methods confirmed this, especially when looking at the critical points in the essays, where InstructGPT led to more uniform ideas and expressions.
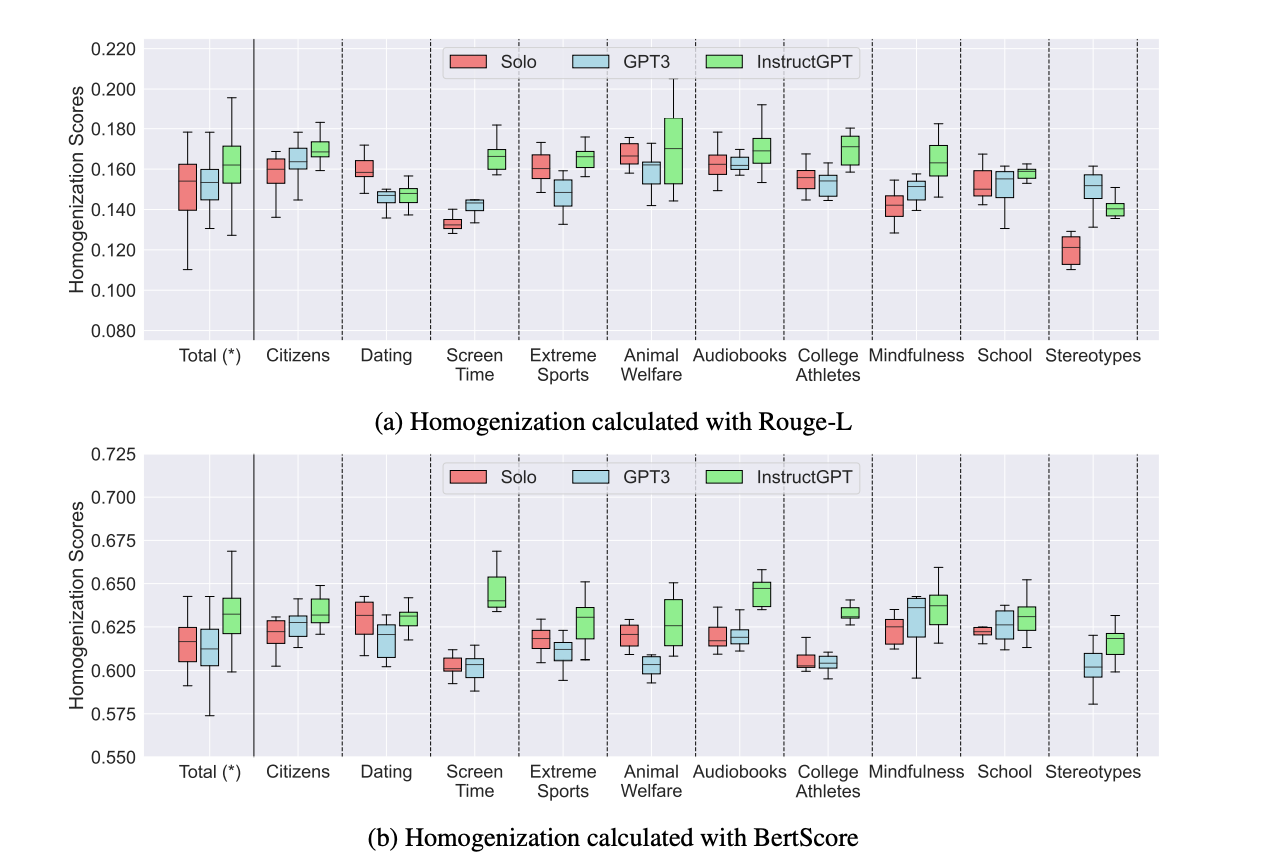
At the keyn point level, the homogenization scores were 0.1536 for solo writers, 0.1578 for GPT-3, and 0.1660 for InstructGPT, with the latter showing a statistically significant increase in similarity.
InstructGPT led to higher levels of uniformity in 7 out of the 10 essay topics, although the effect varied across different subjects. This pattern was consistent both at the key point level and across entire essays.
Interestingly, GPT-3 didn’t have the same effect despite contributing similar text to the essays. The similarity between essays written with GPT-3 was not significantly different from those written without AI, suggesting that not all large language models affect content similarly. While InstructGPT generally outperforms GPT-3 in many areas, this study suggests that its fine-tuning may come at the cost of reducing the diversity in content produced by multiple writers.
Impact of LLMs on Overall Diversity in Writing
The researchers next examine whether the homogenization effect observed when using feedback-tuned language models (LLMs) like InstructGPT leads to a reduction in the overall diversity of essays.
How to Measure Diversity?
To measure diversity, the study looks at each essay collection as a “set of information units” (like n-grams) and calculates the type-token ratio. This ratio helps determine how many unique pieces of information are present compared to the total amount. If the essays are too similar, the whole set resembles one single essay, indicating low diversity. The study focuses on two kinds of information: n-grams to assess variety in language use and key points to gauge diversity in content.
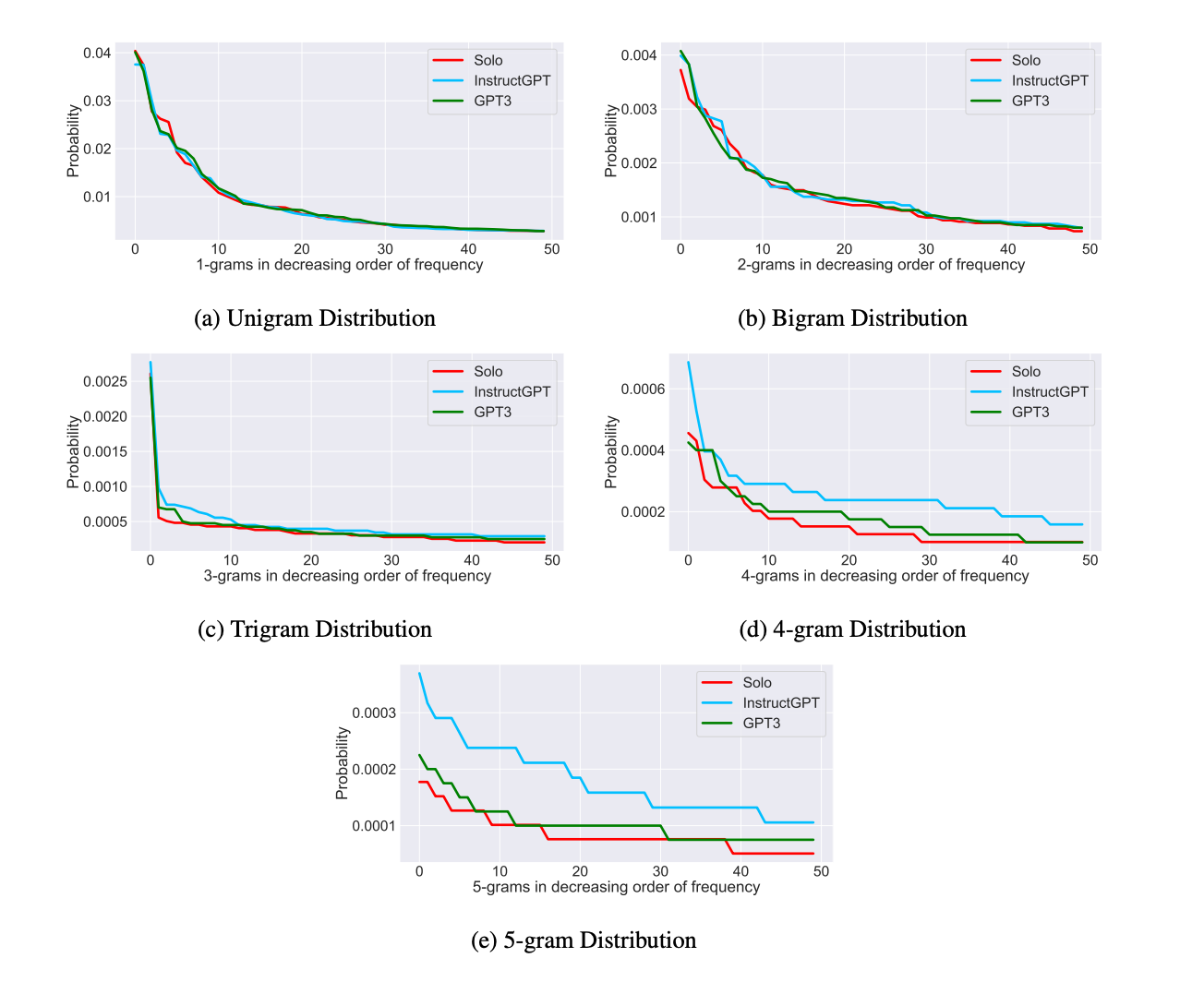
Lexical Diversity
To evaluate linguistic diversity, the study uses n-grams (ranging from 1 to 5) to see how varied the vocabulary is across different essays. The findings reveal that using InstructGPT significantly decreases this variety compared to GPT-3 and the Solo group (those writing without AI assistance).
The Content Diversity Analysis Table shows that this drop in lexical diversity suggests that co-writing with InstructGPT leads to more standardized language. This could be a concern in creative writing, where distinct word choices and expressions are crucial for originality.
Key Point Diversity
To assess the variety of ideas in the essays, the study groups together key arguments from all the essays using a clustering method. The diversity of key points is then measured by how many unique ideas appear across the entire collection.
As shown in the Content Diversity Analysis Table, there’s a noticeable drop in the range of ideas when using InstructGPT. This is concerning because it indicates that InstructGPT makes the language more similar and causes the essays to reflect more of the same ideas, limiting creativity and originality in the arguments presented.

Closing Thoughts:
The study showed us a new axis for evaluating LLMs' impact before deployment. While adapting a model with human feedback leads to an improvement in instruction following, it seems to reduce the content diversity.
Combined with other recent findings that LLMs might be influencing user opinions during the writing process[3], this calls for a careful user-centred evaluation to ensure that these models do not suppress the voice of users in scenarios where personal expression is needed.
Read the full research paper here
AI language models are flooding the internet with a self-reinforcing loop of homogenized writing. This might also homogenize the way we think, and express ourselves.
Tools like ChatGPT may polish and refine our writing, but culturally, they could push us toward a single, uniform perspective — sidelining other languages, viewpoints, and ways of understanding the world.
References:
[1] Vishakh Padmakumar, He he. “DOES WRITING WITH LANGUAGE MODELS REDUCE CONTENT DIVERSITY?”- https://arxiv.org/pdf/2309.05196
[2] Tianyi et al. “BERTSCORE: EVALUATING TEXT GENERATION WITH BERT” — https://arxiv.org/pdf/1904.09675
[3] Maurice Jakesch, Advait Bhat, Daniel Buschek, Lior Zalmanson, and Mor Naaman. 2023. Co-writing with opinionated language models affects users’ views. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems, pages 1–15.
[4] Mina Lee, Percy Liang, and Qian Yang. 2022a. Coauthor: Designing a human-ai collaborative writing dataset for exploring language model capabilities. In Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems, pages 1–19.